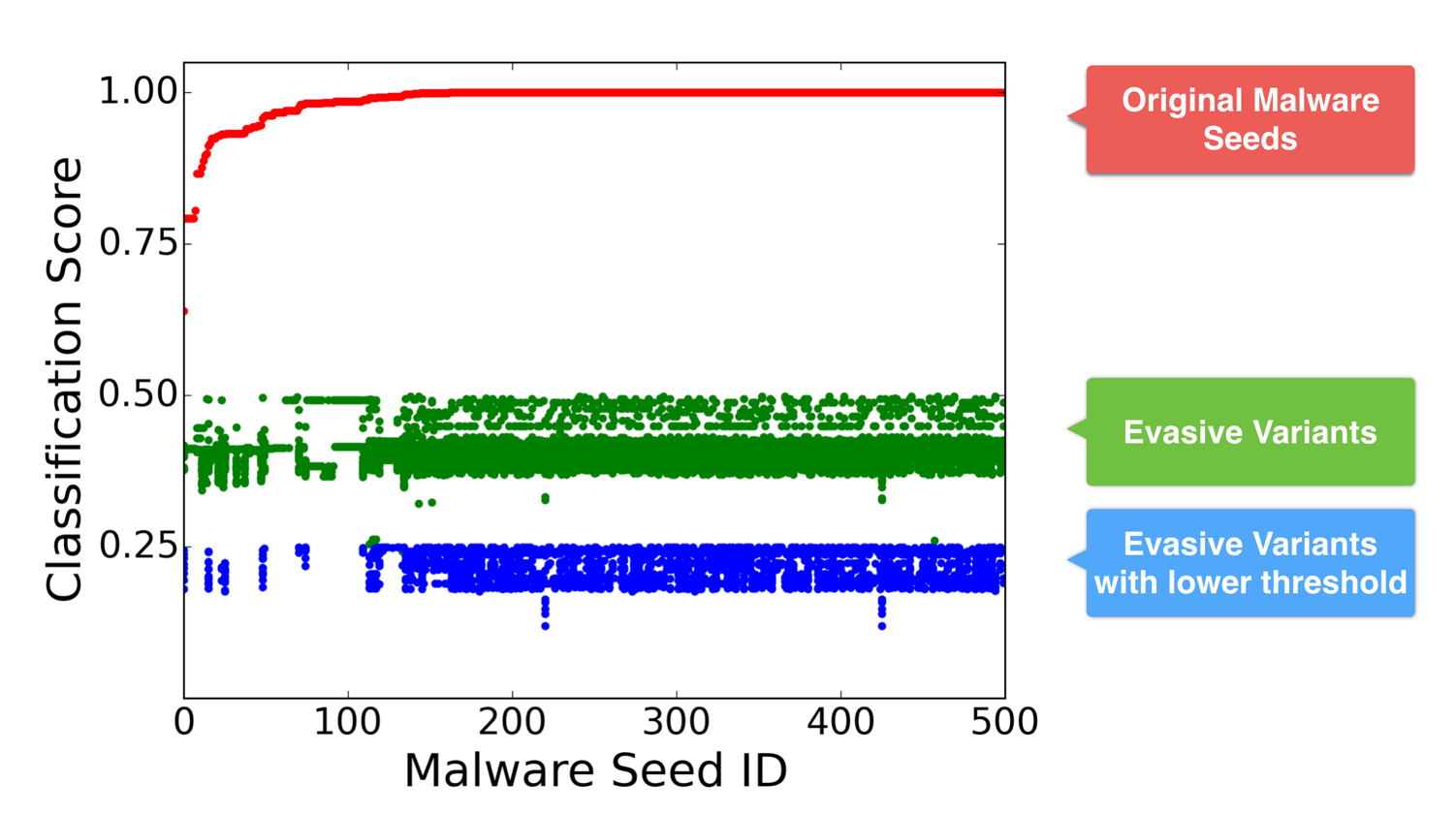
Weilin Xu presented his work on Automatically Evading Classifiers today at the Network and Distributed Systems Security Symposium in San Diego, CA (co-advised by Yanjun Qi and myself). The work demonstrates an automated approach for finding evasive variants of malicious PDF files using genetic programming techniques. Starting with a malicious seed file (that is, a PDF file with the intended malicious behavior, but that is correctly classified as malicious by the target classifier), it heuristically searches for an evasive variant that preserves the malicious behavior of the seed sample but is now classified as benign. The method automatically found an evasive variant for every seed in our test set of 500 malicious PDFs for both of the target classifiers used in the experiment (PDFrate and Hidost).
Slides from the talk are below, the full paper and code is available on the EvadeML.org website.
In addition to the results in the paper, Weilin found some new results examining gmail’s PDF malware classifier. We had hoped the classifier used by gmail would be substantially better than what we found in the research prototype classifiers used in the original experiments, and the initial cross-evasion experiments supported this. Of the 500 evasive variants found for Hidost in the original experiment, 387 were also evasive variants against PDFrate, but only 3 of them were evasive variants against Gmail’s classifier.
From those 3, and some other manual tests, however, Weilin was able to find two very simple transformations (any change to JavaScript such as adding a variable declaration, and adding padding to the file) that are effective at finding evasive variants for 47% of the seeds.

The response we got from Google about this was somewhat disappointing (and very inconsistent with my all previous experiences raising security issues to Google):
Its true, of course, that any kind of static program analysis is
theoretically impossible to do perfectly. But, that doesn’t mean the dominant email provider shouldn’t be trying to do better to detect one of the main vectors for malware distribution today (and there are, we believe, many fairly straightforward and inexpensive things that could be done to do dramatically better than what Gmail is doing today).
The other new result in the talk that isn’t in the paper is the impact of adjusting the target classifier threshold. The search for evasive variants can succeed even at lower thresholds for defining maliciousness (as shown in the slide below, finding evasive variants against PDFrate at the 0.25 maliciousness threshold).