Post by Sicheng Zhu
With the rapid development of deep learning and the explosive growth of unlabeled data, representation learning is becoming increasingly important. It has made impressive applications such as pre-trained language models (e.g., BERT and GPT-3).
Popular as it is, representation learning raises concerns about the robustness of learned representations under adversarial settings. For example, how can we compare the robustness to different representations, and how can we build representations that enable robust downstream classifiers?
In this work, we answer these questions by proposing a notion of adversarial robustness for representations. We show what the best achievable robustness for a downstream classifier is limited by a measurable representation robustness, and provide a training principle for learning adversarially robust representations.
Adversarial Robustness for Representations
Despite various existing criteria for evaluating a representation (e.g., smoothness, sparsity), there is no general way previously known to measure a representation’s robustness under adversarial perturbations. We propose a notion of adversarial robustness for representations based on information-theoretic measures.
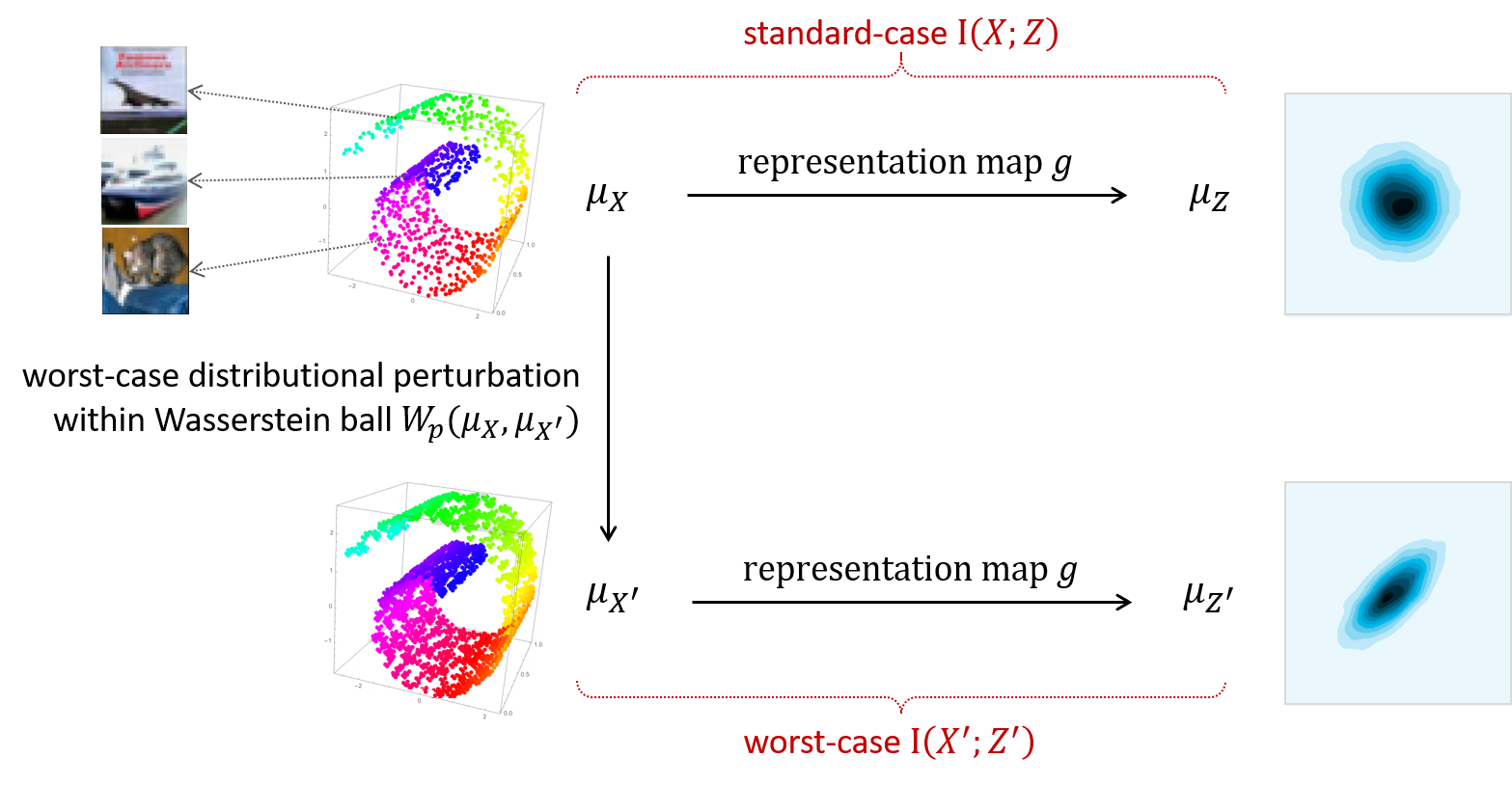
Consider a representation that maps an underlying data distribution to a representation distribution. In this case, we can measure the (standard-case) mutual information between the two distributions. Then by perturbing the data distribution within a Wasserstein ball such that the mutual information term is minimized, we can measure the worst-case mutual information. The representation vulnerability (an opposite notion of robustness) is defined as the difference between the two terms.
This notion enjoys several desired properties in representation learning scenarios-it is scale-invariant, label-free, and compatible with different threat models (including the commonly used Lp norm attacks). Most importantly, we show next that it has a direct relationship with the performance of downstream tasks.
Connecting Representation to Downstream Tasks
If a representation is robust, we show (theoretically in a synthetic setting and empirically in general settings) that a properly trained downstream classifier will perform consistently in both natural and adversarial settings, that is the difference between the natural accuracy and the adversarial accuracy will be small.
If a representation is not robust, we show that no robust downstream classifiers can be built using that representation.
We provide an information-theoretic upper bound for the maximum robust accuracy that can be achieved by any downstream classifier, with respect to the representation robustness. We empirically evaluate the tightness of this bound and find that the vulnerability of internal layer representations of many neural networks is at least one bottleneck for the model to be more robust.
For example, the representation defined by the logit layer of Resnet18 on CIFAR-10 only admits an adversarial accuracy of ~75% for any downstream classifiers.
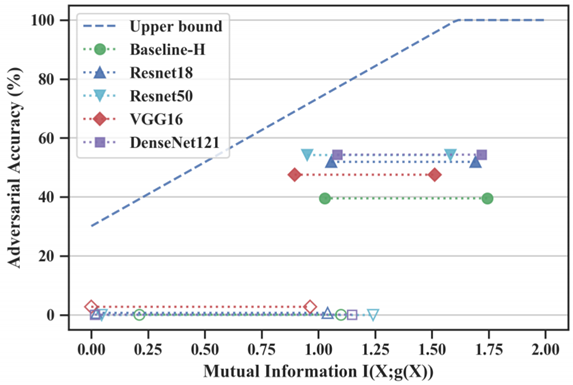
This motivates us to develop a method to learn adversarially robust representations.
A Learning Principle for Robust Representations
Based on the proposed notion, a natural way to learn adversarially robust representations is to directly induce the representation robustness on common representation learning objectives.
We consider a popular representation learning objective — mutual information maximization — as it has impressive performance in practice and many other objectives (e.g., noise contrastive estimation) can be viewed as surrogate losses of this objective. By inducing the representation robustness and setting a specific coefficient, we provide the worst-case mutual information maximization principle for learning adversarially robust representations.
We evaluate the performance of our representation learning principle on four image classification benchmarks (MNIST, Fashion-MNIST, SVHN, and CIFAR-10), here we report on CIFAR-10 (see the paper for the others, where the results are similar).
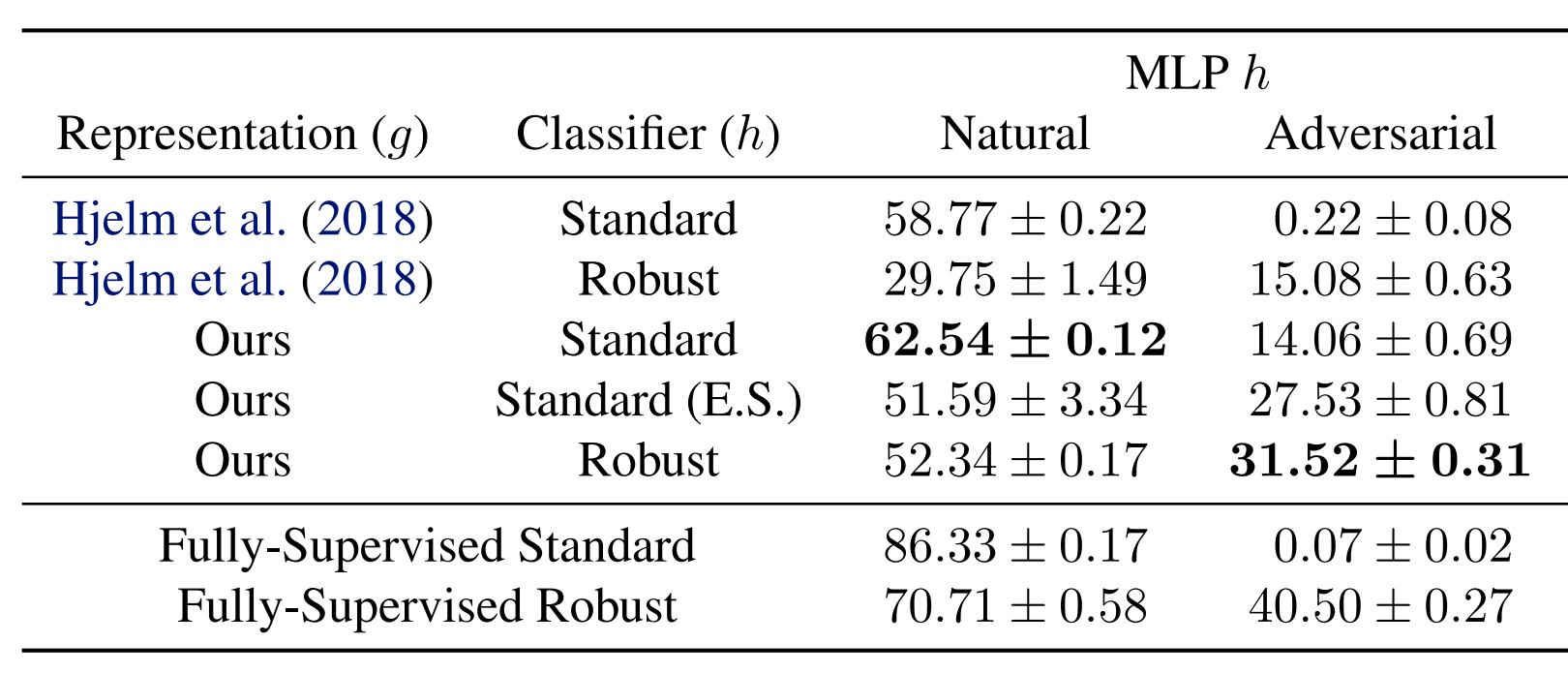
Note that the representations are learned using only unlabeled data and are kept fixed during the training of downstream classifiers. The robust downstream classifier (trained using adversarial training) benefits from the robust representation. It has both better natural accuracy and better adversarial accuracy. The adversarial accuracy of ~31% is even comparable to the fully-supervised robust model with the same architecture.
Even the standard classifier based on our robust representation inherits a non-trivial adversarial accuracy from the robust representation. And more interestingly, they also have better natural accuracy compared to the baseline. This phenomenon is consistent with some recent work using adversarial training to learn pre-trained models and may indicate the better standard generalization of adversarially learned representations.
Saliency Maps
We also visualize the saliency map of our learn representations as side evaluation of adversarial robustness, since the relationship between the interpretability of saliency maps and the adversarial robustness (see Etmann et al.).

The saliency maps of our robust representation (third row) are less noisy and more interpretable than its standard counterpart (second row).
Conclusions
We show that the adversarial robustness for representations is correlated with the achievable robustness for downstream tasks, and that an associated learning principle can be used to produce more robust representations. Our work motivates leaning adversarially robust representations as an intermediate step or as a regularization to circumvent the insurmountable difficulty of directly learning adversarially robust models.
Paper: Sicheng Zhu, Xiao Zhang, and David Evans. Learning Adversarially Robust Representations via Worst-Case Mutual Information Maximization. In International Conference on Machine Learning (ICML 2020), July 2020. [PDF] [Supplemental Materials] [ICML PDF] [arXiv]
Video Presentation (from ICML 2020)