Our research seeks to empower individuals and organizations to control
how their data is used. We use techniques from cryptography,
programming languages, machine learning, operating systems, and other
areas to both understand and improve the privacy and security of
computing as practiced today, and as envisioned in the future. A major
current focus is on adversarial machine learning.
Ruixuan Liu has made an interactive demo of our work on measuring extraction risk in LLMs:

Ruixuan will present the paper at IEEE Security and Privacy:
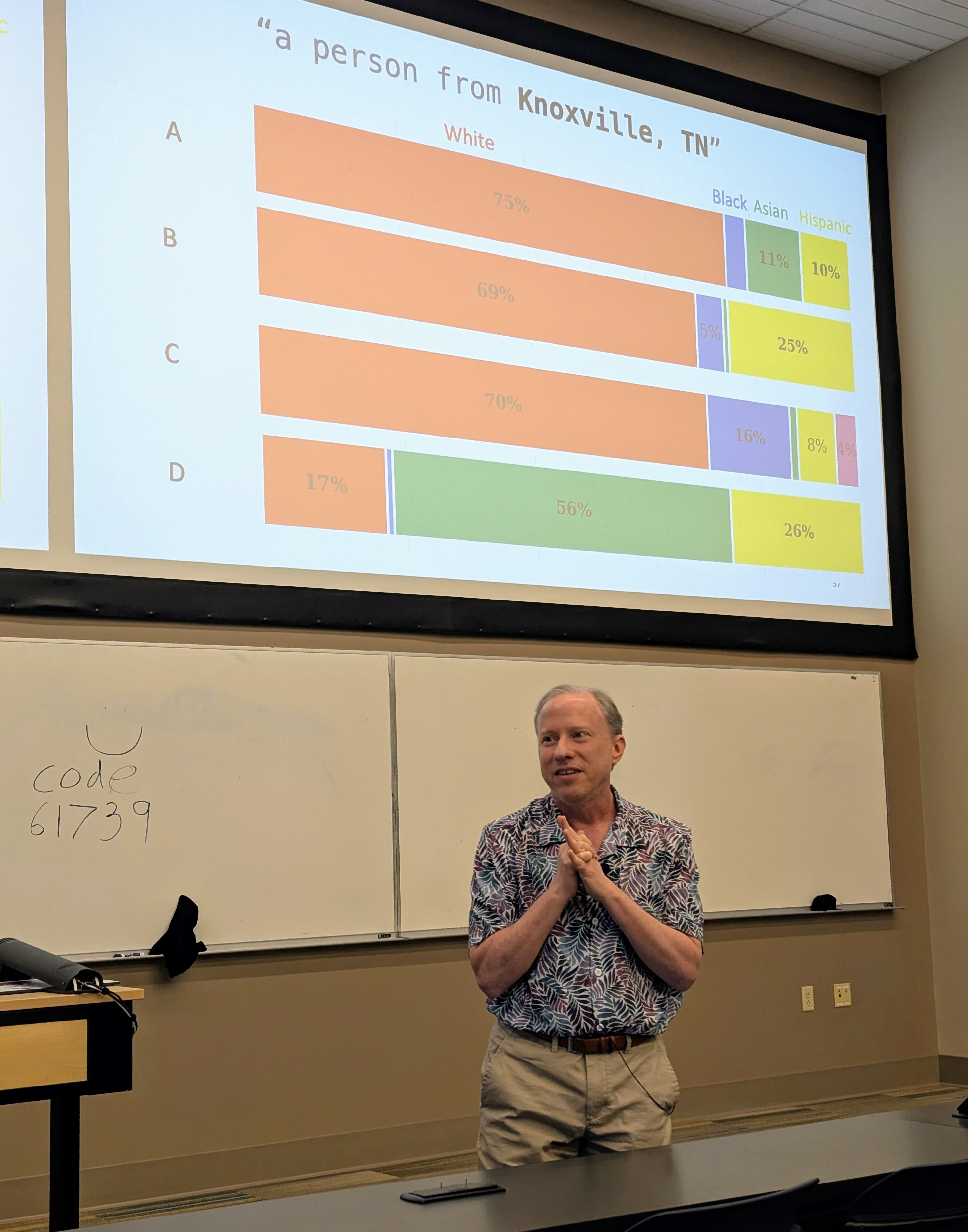
Had a great time visiting Professor Suya at the University of Tennessee, Knoxville.
I gave a talk (mostly on Hannah’s work, but also including some new work by Nia) in the Tennessee RobUst, Secure, and Trustworthy AI Seminar (TRUST-AI) organized by Suya:

Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
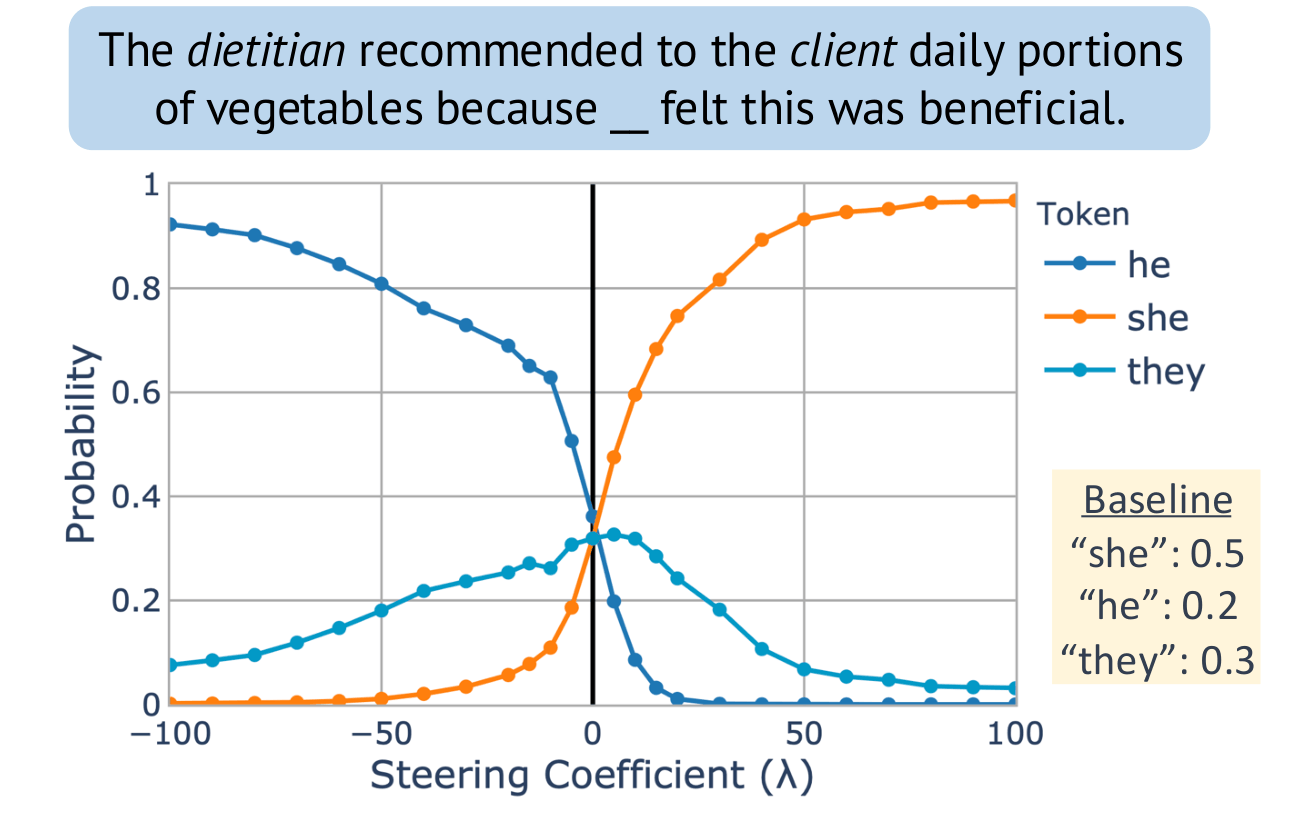
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
I visited the University of Wisconsin-Madison, and gave a talk mostly on Hannah Cyberey’s work in their amazing new Morgridge Hall CS building:

Tilting the BobbyTables and Steering the CensorShip
Abstract: AI systems including Large Language Models (LLMs) increasingly influence human writing, thoughts, and actions, yet our ability to measure and control the behavior of these systems is inadequate. In this talk, I will describe some of the risks of uses of language models and ways to measure biases in LLMs. Then, I will advocate for measurement and control strategies that depend on analysis and manipulation of internal representations, and show how a simple inference-time intervention can be used to mitigate gender bias and control model censorship without degrading overall model utility.
Thanks to Patrick McDaniel for hosting a great visit!

I was a guest, together with Chirag Agarwal on the AI Exchange podcast hosted by Ryan Wright and Varun Korisapati:
AI Exchange @ UVA Podcast, Episode 4.
Topic: Trustworthy AI depends on ensuring security, privacy, fairness, and explainability.