EMNLP: Unsupervised Concept Vector Extraction for Bias Control in LLMs
Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
- Hannah Cyberey, Yangfeng Ji, and David Evans. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China. November 2025. [ACL Anthology [arXiv] [Code]
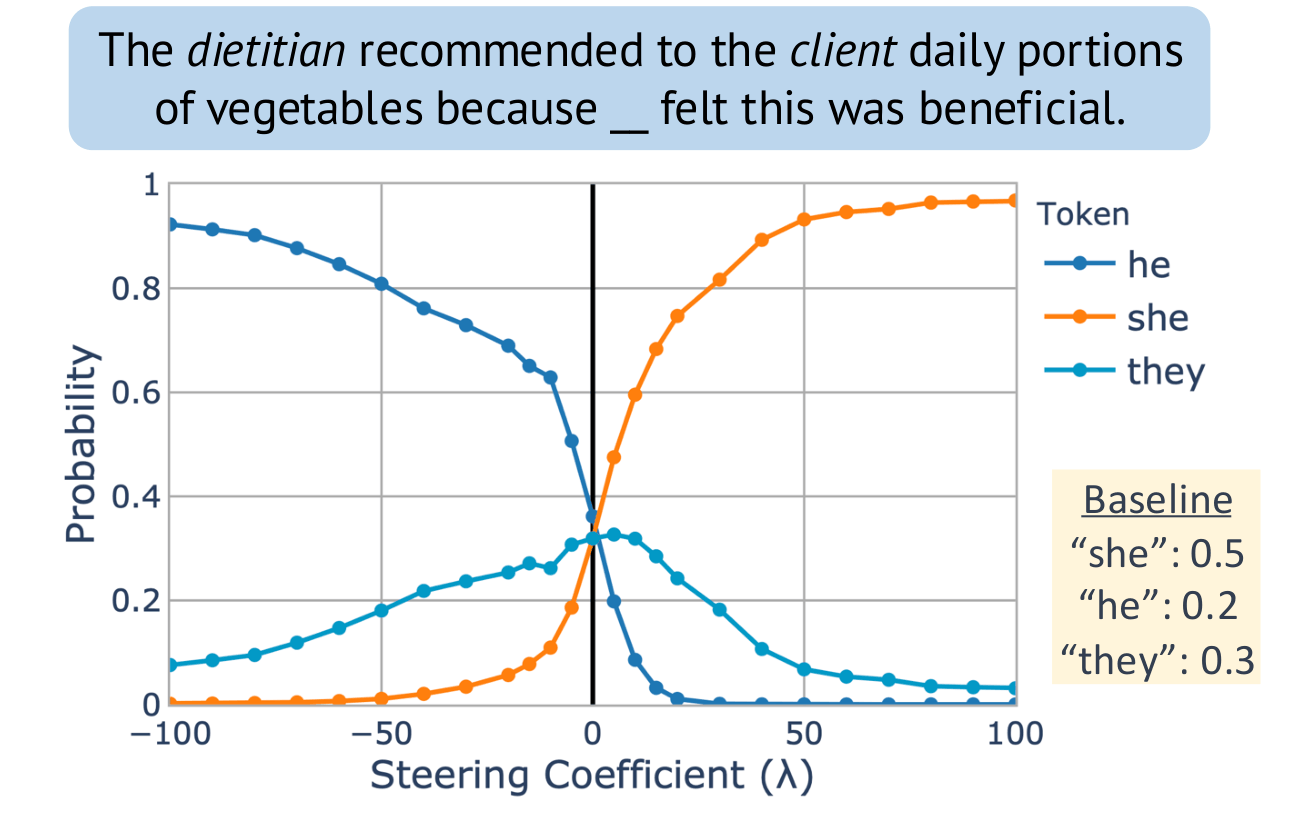
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
Congratulations, Dr. Cyberey!
Congratulations to Hannah Cyberey for successfully defending her PhD thesis!
Large language models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. Yet, they remain unreliable and pose serious social and ethical risks, including reinforcing social stereotypes, spreading misinformation, and facilitating malicious uses. Despite their growing presence in high-stakes settings, current evaluation practices often fail to address these risks.
This dissertation aims to advance the reliability of LLMs by developing rigorous, context-aware evaluation methodologies. We argue that model reliability should be assessed with respect to its intended uses (i.e., how it should operate and under what context) through fine-grained measurements beyond binary judgments. We propose to (1) improve evaluation reliability, (2) design mitigation strategies to control model behavior, and (3) develop auditing techniques for accountability.
Steering the CensorShip

Orthodoxy means not thinking—not needing to think.
(George Orwell, 1984)
Uncovering Representation Vectors for LLM ‘Thought’ Control
Hannah Cyberey’s blog post summarizes our work on controlling the censorship imposed through refusal and thought suppression in model outputs.
Paper: Hannah Cyberey and David Evans. Steering the CensorShip: Uncovering Representation Vectors for LLM “Thought” Control. 23 April 2025.
Demos:
-
🐳 Steeing Thought Suppression with DeepSeek-R1-Distill-Qwen-7B (this demo should work for everyone!)
-
🦙 Steering Refusal–Compliance with Llama-3.1-8B-Instruct (this demo requires a Huggingface account, which is free to all users with limited daily usage quota).
Is Taiwan a Country?
I gave a short talk at an NSF workshop to spark research collaborations between researchers in Taiwan and the United States. My talk was about work Hannah Cyberey is leading on steering the internal representations of LLMs:

Steering around Censorship
Taiwan-US Cybersecurity Workshop
Arlington, Virginia
3 March 2025