EMNLP: Unsupervised Concept Vector Extraction for Bias Control in LLMs
Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
- Hannah Cyberey, Yangfeng Ji, and David Evans. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China. November 2025. [ACL Anthology [arXiv] [Code]
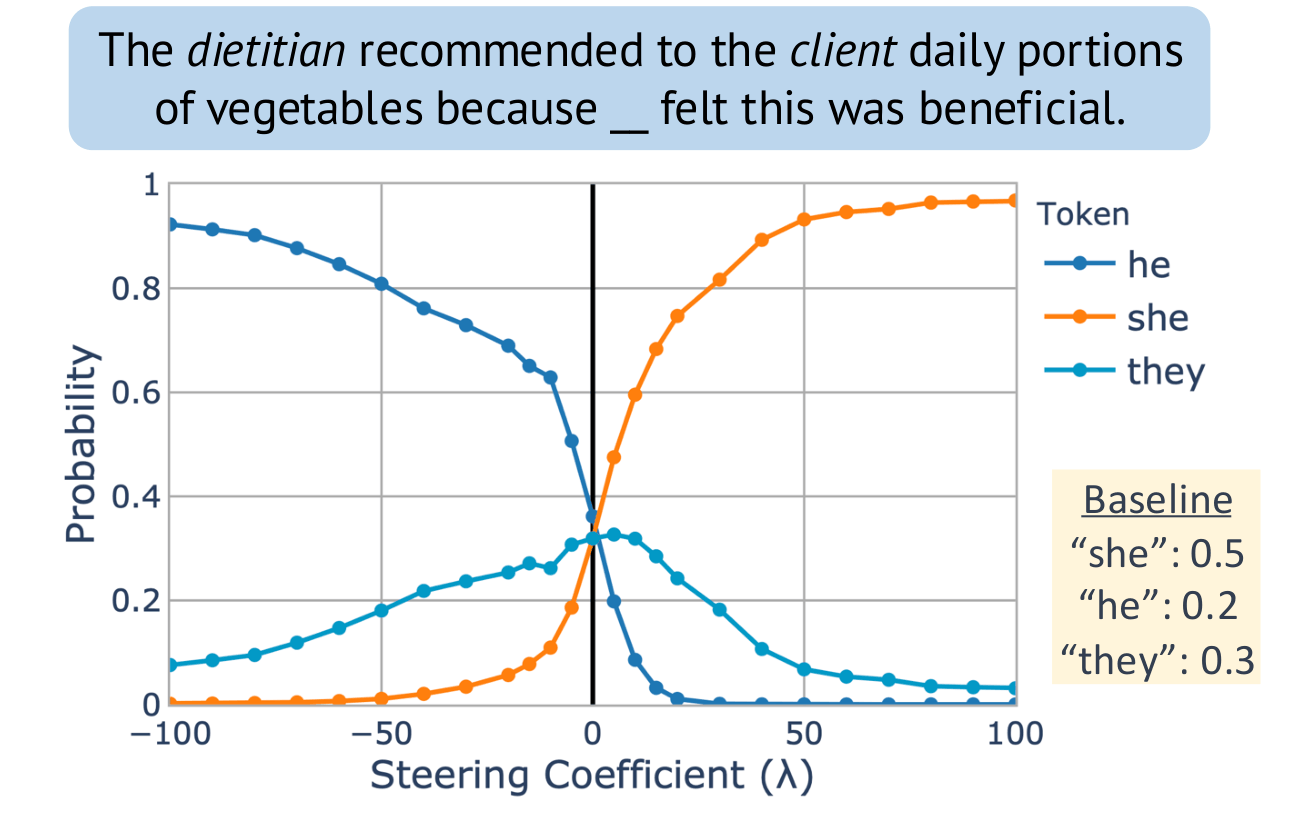
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
Is Taiwan a Country?
I gave a short talk at an NSF workshop to spark research collaborations between researchers in Taiwan and the United States. My talk was about work Hannah Cyberey is leading on steering the internal representations of LLMs:

Steering around Censorship
Taiwan-US Cybersecurity Workshop
Arlington, Virginia
3 March 2025
The Mismeasure of Man and Models
Evaluating Allocational Harms in Large Language Models
Blog post written by Hannah Chen
Our work considers allocational harms that arise when model predictions are used to distribute scarce resources or opportunities.
Current Bias Metrics Do Not Reliably Reflect Allocation Disparities
Several methods have been proposed to audit large language models (LLMs) for bias when used in critical decision-making, such as resume screening for hiring. Yet, these methods focus on predictions, without considering how the predictions are used to make decisions. In many settings, making decisions involve prioritizing options due to limited resource constraints. We find that prediction-based evaluation methods, which measure bias as the average performance gap (δ) in prediction outcomes, do not reliably reflect disparities in allocation decision outcomes.
Balancing Tradeoffs between Fickleness and Obstinacy in NLP Models
Post by Hannah Chen.
Our work on balanced adversarial training looks at how to train models that are robust to two different types of adversarial examples:
Hannah Chen, Yangfeng Ji, David Evans. Balanced Adversarial Training: Balancing Tradeoffs between Fickleness and Obstinacy in NLP Models. In The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, 7-11 December 2022. [ArXiv]
Adversarial Examples
At the broadest level, an adversarial example is an input crafted intentionally to confuse a model. However, most work focus on the defintion as an input constructed by applying a small perturbation that preserves the ground truth label but changes model’s output (Goodfellow et al., 2015). We refer it as a fickle adversarial example. On the other hand, attackers can target an opposite objective where the inputs are made with minimal changes that change the ground truth labels but retain model’s predictions (Jacobsen et al., 2018). We refer these malicious inputs as obstinate adversarial examples.
Pointwise Paraphrase Appraisal is Potentially Problematic
Hannah Chen presented her paper on Pointwise Paraphrase Appraisal is Potentially Problematic at the ACL 2020 Student Research Workshop:
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.