Beyond Indistinguishability
Ruixuan Liu has made an interactive demo of our work on measuring extraction risk in LLMs:

Ruixuan will present the paper at IEEE Security and Privacy:
- Ruixuan Liu, David Evans, Li Xiong. Beyond Indistinguishability: Measuring Extraction Risk in LLM APIs. In 47th IEEE Symposium on Security and Privacy (Oakland). [arXiv] [Code]
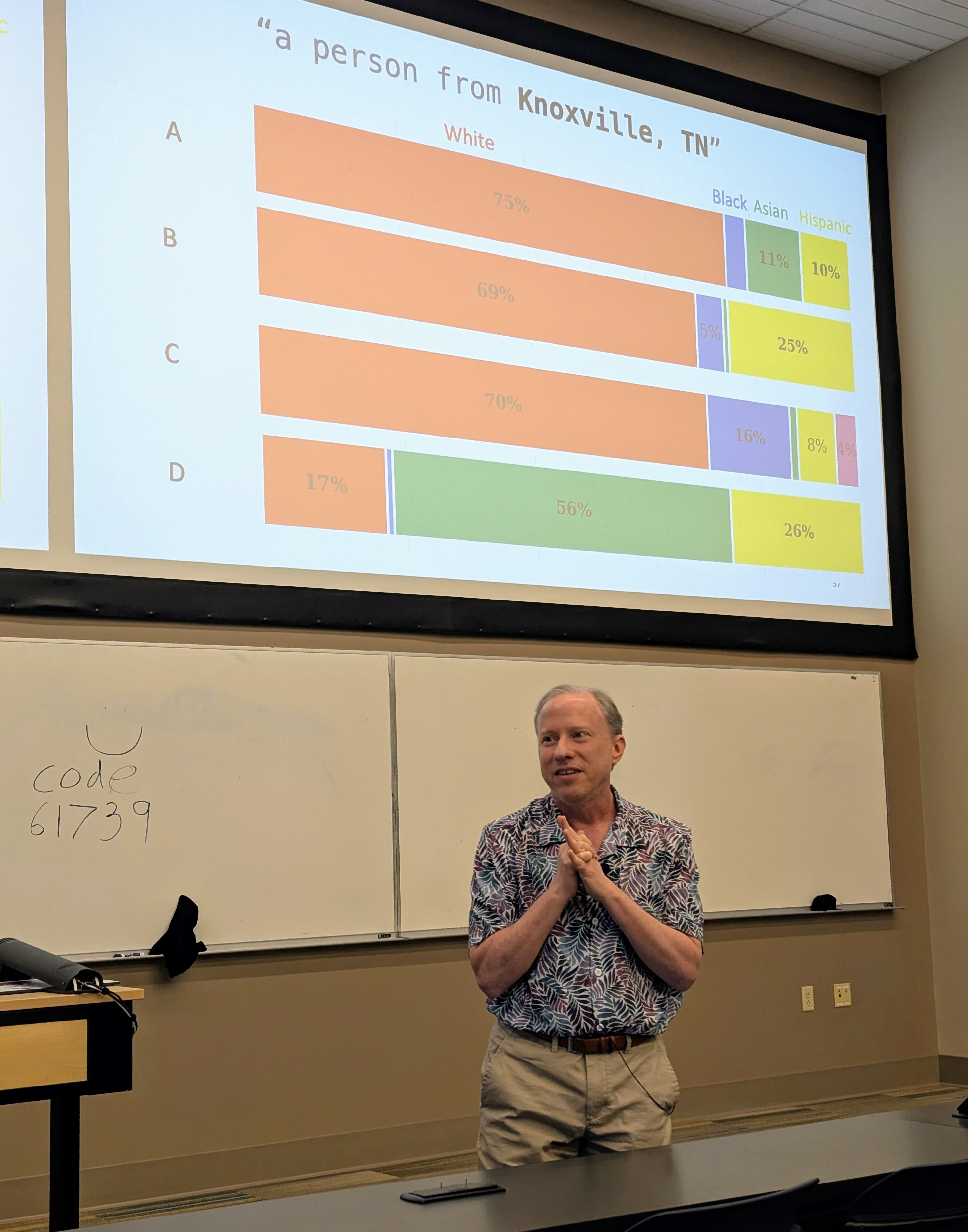
Visit to University of Tennessee
Had a great time visiting Professor Suya at the University of Tennessee, Knoxville.
I gave a talk (mostly on Hannah’s work, but also including some new work by Nia) in the Tennessee RobUst, Secure, and Trustworthy AI Seminar (TRUST-AI) organized by Suya:
- Tilting the BobbyTables and Steering the CensorShip, TRUST-AI Distinguished Seminar Series and Center for Social Theory. University of Tennessee, Knoxville. 27 March 2026.

|

|
 |
|
EMNLP: Unsupervised Concept Vector Extraction for Bias Control in LLMs
Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
- Hannah Cyberey, Yangfeng Ji, and David Evans. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China. November 2025. [ACL Anthology [arXiv] [Code]
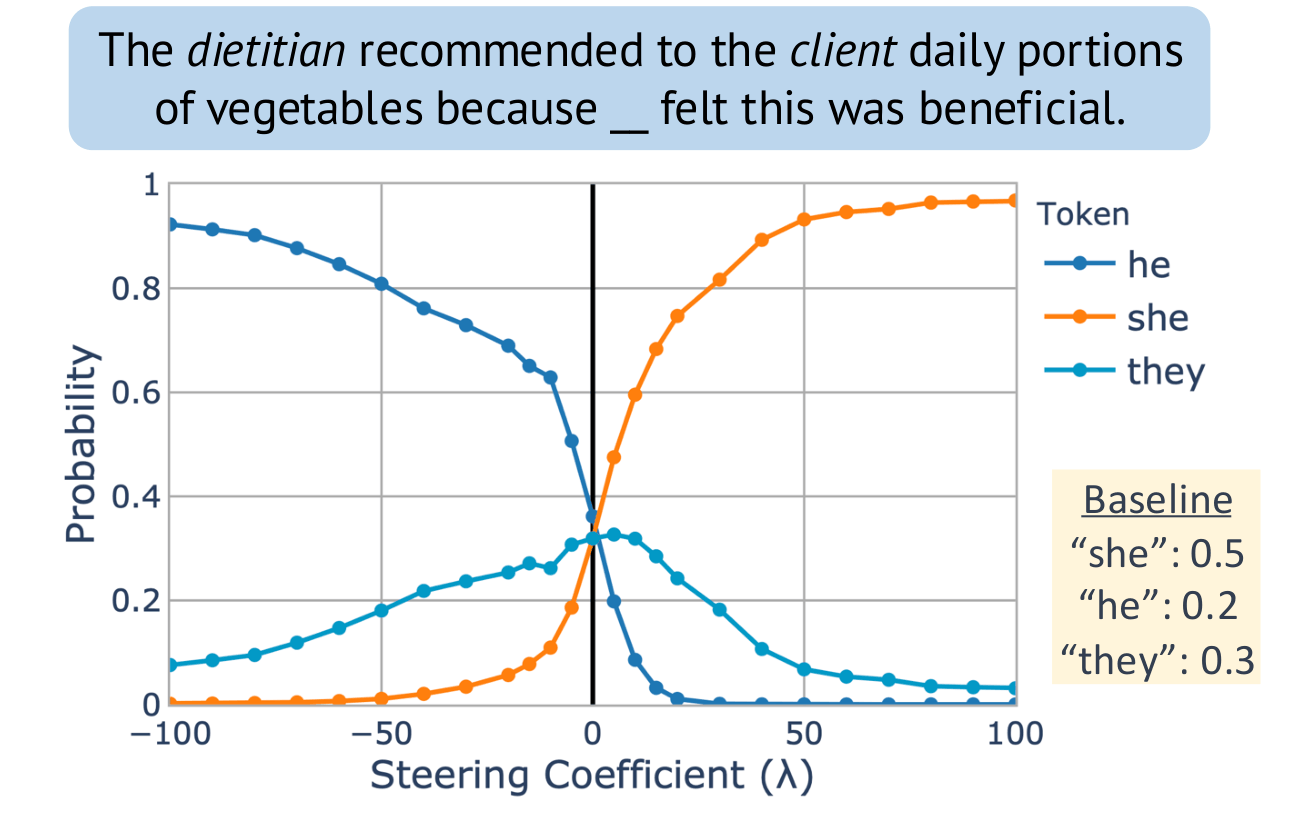
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
TMLR: Inference-time Methods for LLM Reliability
Our paper on evaluating inference-time methods (like Chain of Thought) to improve LLM reliability has been published in Transactions on Machine Learning Research:
- Michael Jerge and David Evans. Pitfalls in Evaluating Inference-time Methods for Improving LLM Reliability. Transactions on Machine Learning Research, June 2025. [PDF] [OpenReview] [Code]
The heatmap shows the deviation from baseline accuracy for Chain of Thought, Self-Consistency, ReAct, Tree of Thoughts, Graph of Thoughts, and LLM Multi-Agent Debate applied across different models and benchmarks. Positive deviations (in green) indicate improvements over the unaided model (baseline), while negative deviations (in red) indicate performance decline:
Is Taiwan a Country?
I gave a short talk at an NSF workshop to spark research collaborations between researchers in Taiwan and the United States. My talk was about work Hannah Cyberey is leading on steering the internal representations of LLMs:

Steering around Censorship
Taiwan-US Cybersecurity Workshop
Arlington, Virginia
3 March 2025
Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?
Anshuman Suri and Pratyush Maini wrote a blog about the EMNLP 2024 best paper award winner: Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?.
As we explored in Do Membership Inference Attacks Work on Large Language Models?, to test a membership inference attack it is essentail to have a candidate set where the members and non-members are from the same distribution. If the distributions are different, the ability of an attack to distinguish members and non-members is indicative of distribution inference, not necessarily membership inference.
Common Way To Test for Leaks in Large Language Models May Be Flawed
UVA News has an article on our LLM membership inference work: Common Way To Test for Leaks in Large Language Models May Be Flawed: UVA Researchers Collaborated To Study the Effectiveness of Membership Inference Attacks, Eric Williamson, 13 November 2024.