Congratulations, Dr. Suri!
Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?
Anshuman Suri and Pratyush Maini wrote a blog about the EMNLP 2024 best paper award winner: Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?.
As we explored in Do Membership Inference Attacks Work on Large Language Models?, to test a membership inference attack it is essentail to have a candidate set where the members and non-members are from the same distribution. If the distributions are different, the ability of an attack to distinguish members and non-members is indicative of distribution inference, not necessarily membership inference.
Common Way To Test for Leaks in Large Language Models May Be Flawed
UVA News has an article on our LLM membership inference work: Common Way To Test for Leaks in Large Language Models May Be Flawed: UVA Researchers Collaborated To Study the Effectiveness of Membership Inference Attacks, Eric Williamson, 13 November 2024.
Congratulations, Dr. Suri!
Congratulations to Anshuman Suri for successfully defending his PhD thesis!

Tianhao Wang, Dr. Anshuman Suri, Nando Fioretto, Cong Shen
On Screen: David Evans, Giuseppe Ateniese
Using machine learning models comes at the risk of leaking information about data used in their training and deployment. This leakage can expose sensitive information about properties of the underlying data distribution, data from participating users, or even individual records in the training data. In this dissertation, we develop and evaluate novel methods to quantify and audit such information disclosure at three granularities: distribution, user, and record.
SaTML Talk: SoK: Pitfalls in Evaluating Black-Box Attacks
Anshuman Suri’s talk at IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) is now available:
See the earlier blog post for more on the work, and the paper at https://arxiv.org/abs/2310.17534.
Do Membership Inference Attacks Work on Large Language Models?
Membership inference attacks (MIAs) attempt to predict whether a particular datapoint is a member of a target model’s training data. Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs).
We perform a large-scale evaluation of MIAs over a suite of language models (LMs) trained on the Pile, ranging from 160M to 12B parameters. We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains. Our further analyses reveal that this poor performance can be attributed to (1) the combination of a large dataset and few training iterations, and (2) an inherently fuzzy boundary between members and non-members.
SoK: Pitfalls in Evaluating Black-Box Attacks
Post by Anshuman Suri and Fnu Suya
Much research has studied black-box attacks on image classifiers, where adversaries generate adversarial examples against unknown target models without having access to their internal information. Our analysis of over 164 attacks (published in 102 major security, machine learning and security conferences) shows how these works make different assumptions about the adversary’s knowledge.
The current literature lacks cohesive organization centered around the threat model. Our SoK paper (to appear at IEEE SaTML 2024) introduces a taxonomy for systematizing these attacks and demonstrates the importance of careful evaluations that consider adversary resources and threat models.
SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Our paper on the use of cryptographic-style games to model inference privacy is published in IEEE Symposium on Security and Privacy (Oakland):
Giovanni Cherubin, , Boris Köpf, Andrew Paverd, Anshuman Suri, Shruti Tople, and Santiago Zanella-Béguelin. SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning. IEEE Symposium on Security and Privacy, 2023. [Arxiv]
Tired of diverse definitions of machine learning privacy risks? Curious about game-based definitions? In our paper, we present privacy games as a tool for describing and analyzing privacy risks in machine learning. Join us on May 22nd, 11 AM @IEEESSP '23 https://t.co/NbRuTmHyd2 pic.twitter.com/CIzsT7UY4b
CVPR 2023: Manipulating Transfer Learning for Property Inference
Manipulating Transfer Learning for Property Inference
Transfer learning is a popular method to train deep learning models efficiently. By reusing parameters from upstream pre-trained models, the downstream trainer can use fewer computing resources to train downstream models, compared to training models from scratch.
The figure below shows the typical process of transfer learning for vision tasks:
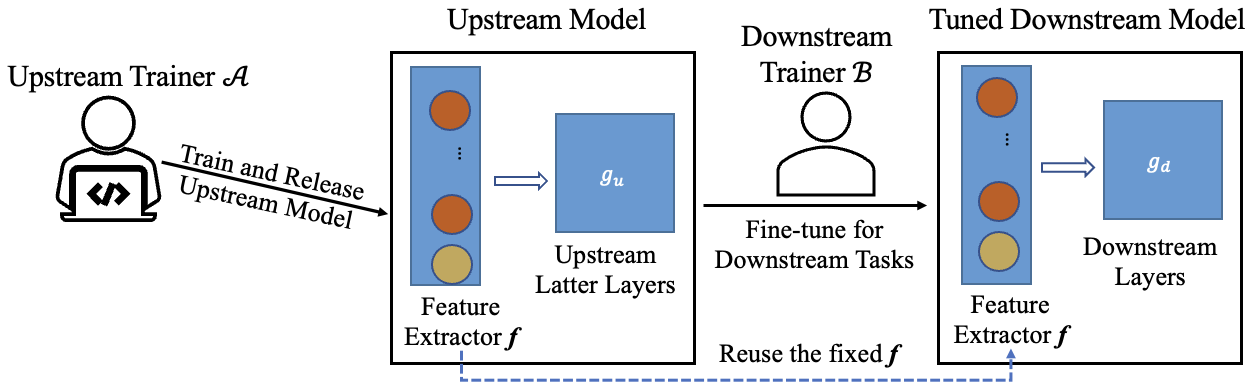
However, the nature of transfer learning can be exploited by a malicious upstream trainer, leading to severe risks to the downstream trainer.
MICO Challenge in Membership Inference
Anshuman Suri wrote up an interesting post on his experience with the MICO Challenge, a membership inference competition that was part of SaTML. Anshuman placed second in the competition (on the CIFAR data set), where the metric is highest true positive rate at a 0.1 false positive rate over a set of models (some trained using differential privacy and some without).
Anshuman’s post describes the methods he used and his experience in the competition: My submission to the MICO Challenge.