Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?
Anshuman Suri and Pratyush Maini wrote a blog about the EMNLP 2024 best paper award winner: Reassessing EMNLP 2024’s Best Paper: Does Divergence-Based Calibration for Membership Inference Attacks Hold Up?.
As we explored in Do Membership Inference Attacks Work on Large Language Models?, to test a membership inference attack it is essentail to have a candidate set where the members and non-members are from the same distribution. If the distributions are different, the ability of an attack to distinguish members and non-members is indicative of distribution inference, not necessarily membership inference.
Common Way To Test for Leaks in Large Language Models May Be Flawed
UVA News has an article on our LLM membership inference work: Common Way To Test for Leaks in Large Language Models May Be Flawed: UVA Researchers Collaborated To Study the Effectiveness of Membership Inference Attacks, Eric Williamson, 13 November 2024.
Congratulations, Dr. Suri!
Congratulations to Anshuman Suri for successfully defending his PhD thesis!

Tianhao Wang, Dr. Anshuman Suri, Nando Fioretto, Cong Shen
On Screen: David Evans, Giuseppe Ateniese
Using machine learning models comes at the risk of leaking information about data used in their training and deployment. This leakage can expose sensitive information about properties of the underlying data distribution, data from participating users, or even individual records in the training data. In this dissertation, we develop and evaluate novel methods to quantify and audit such information disclosure at three granularities: distribution, user, and record.
Do Membership Inference Attacks Work on Large Language Models?
Membership inference attacks (MIAs) attempt to predict whether a particular datapoint is a member of a target model’s training data. Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs).
We perform a large-scale evaluation of MIAs over a suite of language models (LMs) trained on the Pile, ranging from 160M to 12B parameters. We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains. Our further analyses reveal that this poor performance can be attributed to (1) the combination of a large dataset and few training iterations, and (2) an inherently fuzzy boundary between members and non-members.
CVPR 2023: Manipulating Transfer Learning for Property Inference
Manipulating Transfer Learning for Property Inference
Transfer learning is a popular method to train deep learning models efficiently. By reusing parameters from upstream pre-trained models, the downstream trainer can use fewer computing resources to train downstream models, compared to training models from scratch.
The figure below shows the typical process of transfer learning for vision tasks:
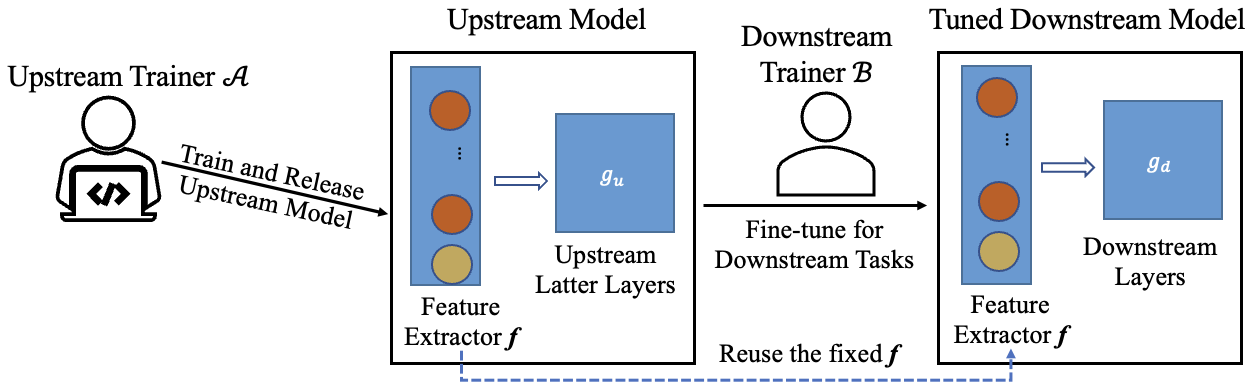
However, the nature of transfer learning can be exploited by a malicious upstream trainer, leading to severe risks to the downstream trainer.
Dissecting Distribution Inference
(Cross-post by Anshuman Suri)
Distribution inference attacks aims to infer statistical properties of data used to train machine learning models. These attacks are sometimes surprisingly potent, as we demonstrated in previous work.
KL Divergence Attack
Most attacks against distribution inference involve training a meta-classifier, either using model parameters in white-box settings (Ganju et al., Property Inference Attacks on Fully Connected Neural Networks using Permutation Invariant Representations, CCS 2018), or using model predictions in black-box scenarios (Zhang et al., Leakage of Dataset Properties in Multi-Party Machine Learning, USENIX 2021). While other black-box were proposed in our prior work, they are not as accurate as meta-classifier-based methods, and require training shadow models nonetheless (Suri and Evans, Formalizing and Estimating Distribution Inference Risks, PETS 2022).
Cray Distinguished Speaker: On Leaky Models and Unintended Inferences
Here’s the slides from my Cray Distinguished Speaker talk on On Leaky Models and Unintended Inferences: [PDF]

The chatGPT limerick version of my talk abstract is much better than mine:
A machine learning model, oh so grand
With data sets that it held in its hand
It performed quite well
But secrets to tell
And an adversary’s tricks it could not withstand.
Thanks to Stephen McCamant and Kangjie Lu for hosting my visit, and everyone at University of Minnesota. Also great to catch up with UVA BSCS alumn, Stephen J. Guy.
Attribute Inference attacks are really Imputation
Post by Bargav Jayaraman
Attribute inference attacks have been shown by prior works to pose privacy threat against ML models. However, these works assume the knowledge of the training distribution and we show that in such cases these attacks do no better than a data imputataion attack that does not have access to the model. We explore the attribute inference risks in the cases where the adversary has limited or no prior knowledge of the training distribution and show that our white-box attribute inference attack (that uses neuron activations to infer the unknown sensitive attribute) surpasses imputation in these data constrained cases. This attack uses the training distribution information leaked by the model, and thus poses privacy risk when the distribution is private.
BIML: What Machine Learnt Models Reveal
I gave a talk in the Berryville Institute of Machine Learning in the Barn series on What Machine Learnt Models Reveal, which is now available as an edited video:
David Evans, a professor of computer science researching security and privacy at the University of Virginia, talks about data leakage risk in ML systems and different approaches used to attack and secure models and datasets. Juxtaposing adversarial risks that target records and those aimed at attributes, David shows that differential privacy cannot capture all inference risks, and calls for more research based on privacy experiments aimed at both datasets and distributions.
On the Risks of Distribution Inference
(Cross-post by Anshuman Suri)
Inference attacks seek to infer sensitive information about the training process of a revealed machine-learned model, most often about the training data.
Standard inference attacks (which we call “dataset inference attacks”) aim to learn something about a particular record that may have been in that training data. For example, in a membership inference attack (Reza Shokri et al., Membership Inference Attacks Against Machine Learning Models, IEEE S&P 2017), the adversary aims to infer whether or not a particular record was included in the training data.