Post by Bargav Jayaraman
Attribute inference attacks have been shown by prior works to pose privacy threat against ML models. However, these works assume the knowledge of the training distribution and we show that in such cases these attacks do no better than a data imputataion attack that does not have access to the model. We explore the attribute inference risks in the cases where the adversary has limited or no prior knowledge of the training distribution and show that our white-box attribute inference attack (that uses neuron activations to infer the unknown sensitive attribute) surpasses imputation in these data constrained cases. This attack uses the training distribution information leaked by the model, and thus poses privacy risk when the distribution is private.
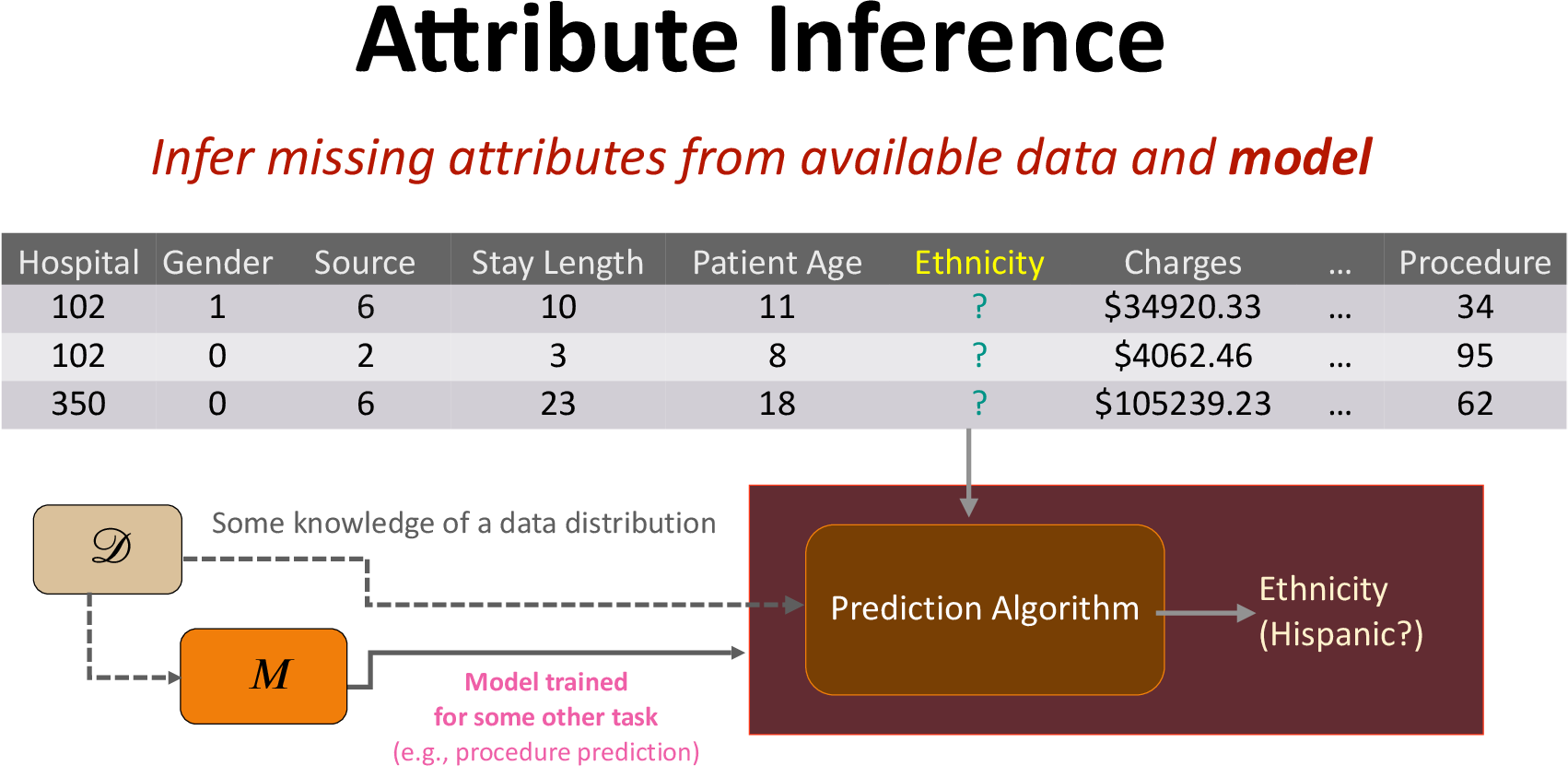
Prior Attribute Inference Attacks Do Not Pose Privacy Risk
Prior works in attribute inference have mainly considered black-box access to the machine learning model and show successful attribute inference (in terms of attack accuracy) in the case where the adversary has access to the underlying training distribution. Our experiments show that in such cases even an imputation adversary, without access to the model, can achieve high inference accuracy, as shown in the table below:
| Census (Race) | Texas-100X (Ethnicity) | ||||
|---|---|---|---|---|---|
| Predict Most Common | 0.78 | 0.72 | |||
| Imputation Attack | 0.82 | 0.72 | |||
| Yeom et al. Attack | 0.65 | 0.58 | |||
| Mehnaz et al. Attack | 0.06 | 0.60 | |||
| WCAI (Our version of Yeom) | 0.83 | 0.74 |
Thus, these attribute inference attacks seem to not pose any significant privacy risk as the adversary can have similar attack success without access to the model.
Sensitive Value Inference
Attribute inference risk is inherently asymmetric — identifying a record with minority attribute value (such as Hispanic ethnicity) does not have the same risk as identifying a record with majority attribute value (such as Non-Hispanic ethnicity). Accuracy metric does not capture this. Moreover, attribute inference definition considered by prior works also fails to distinguish these cases. We propose studying a fine-grained version of attribute inference, called sensitive value inference, that considers the attack success in inferring a particular sensitive attribute outcome.
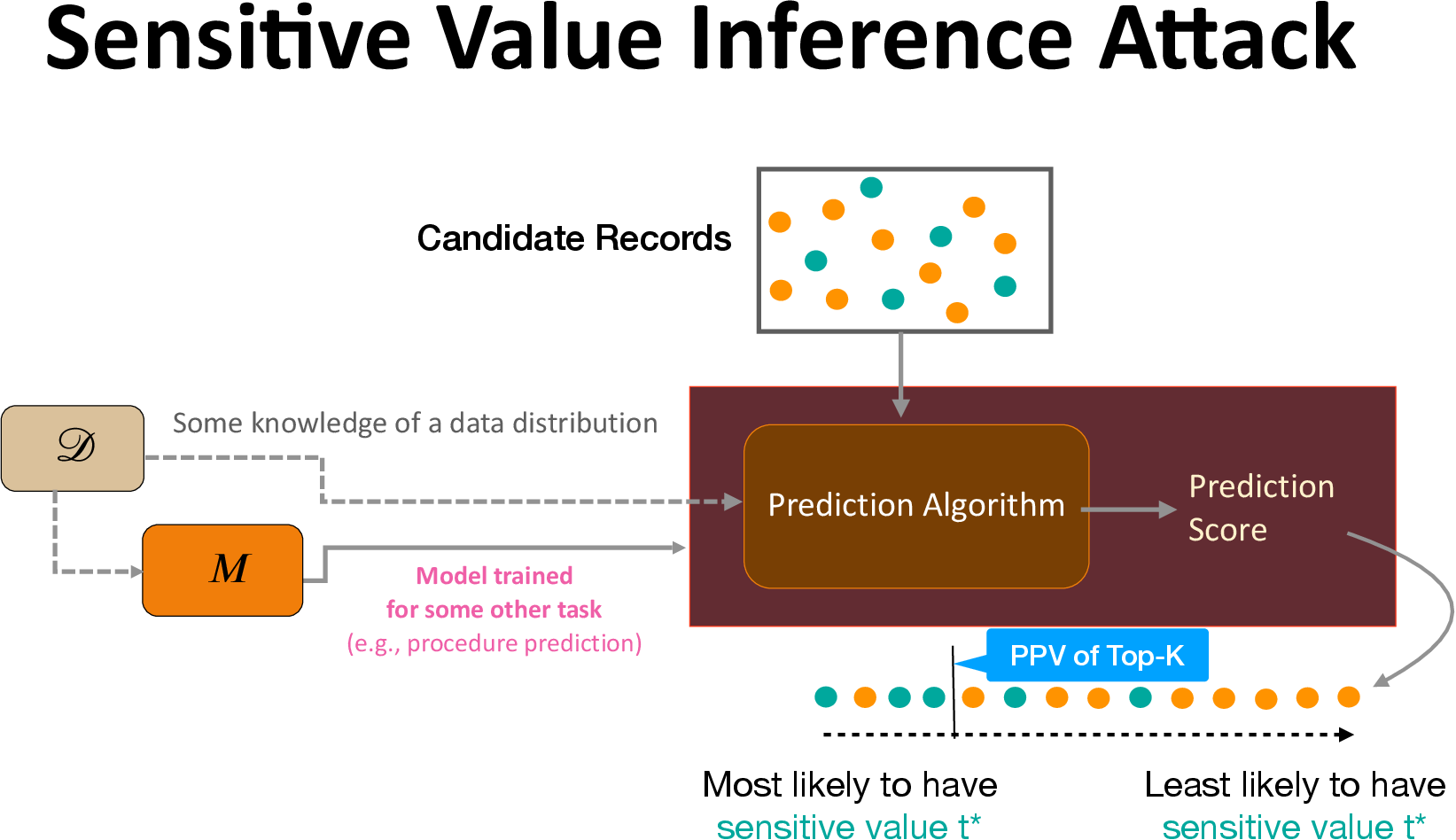
We measure the attack success by evaluating the positive predictive value (PPV) of the inference attack in predicting the top-k candidate records with the sensitive outcome. The PPV values are between 0 and 1, where a higher value denotes a greater attack precision.
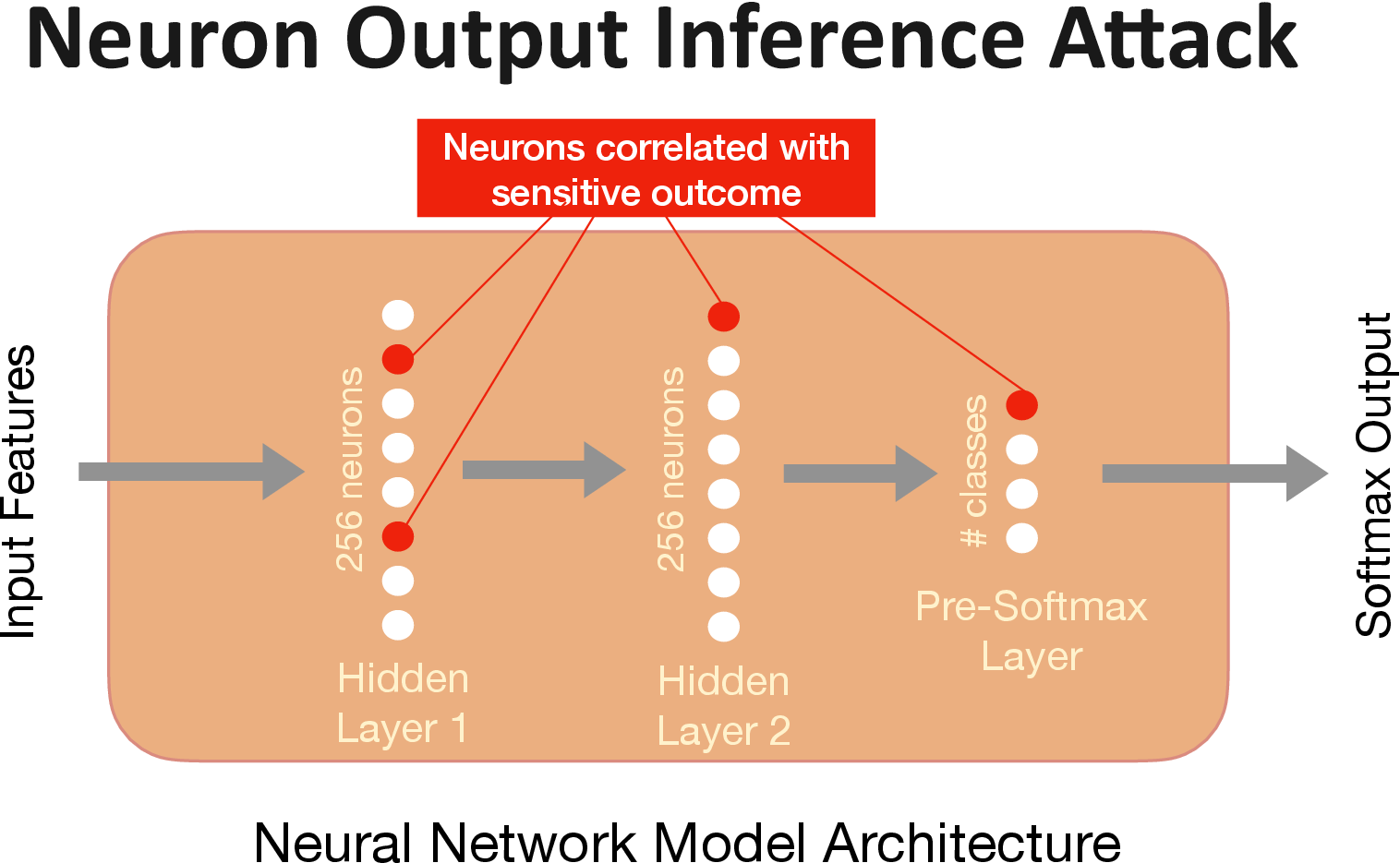
The Neuron Output Attack
Our novel neuron output based white-box attack finds the neurons that are most correlated with the sensitive value. For this attack, the adversary selects records from a hold-out set, sets the unknown target attribute to the sensitive value, and queries the model. The adversary then identifies the set of neurons that have higher activations on average for the records with the sensitive value as the ground-truth. The adversary then uses the aggregate output of these neurons to identify the candidate records with sensitive value.
Model Leaks Distribution Information
In our experiments, we vary the distribution available to the adversary and also the amount of data from the respective distribution the adversary has to train the inference attack. When the adversary has access to >5000 records from the training distribition (not the same as the training set records), imputataion outperforms all the attribute inference attacks (incuding our white-box neuron output attack). As we decrease the known set size to 500 and 50, the imputation PPV decreases drastically whereas our neuron output attack continues to achieve high PPV. Thus the attack is able to take advantage of the training distribution information leaked by the model. The figure below depicts the case where the adversary has 500 records from the training distribution, and as shown, the neuron output attack surpasses the imputataion.
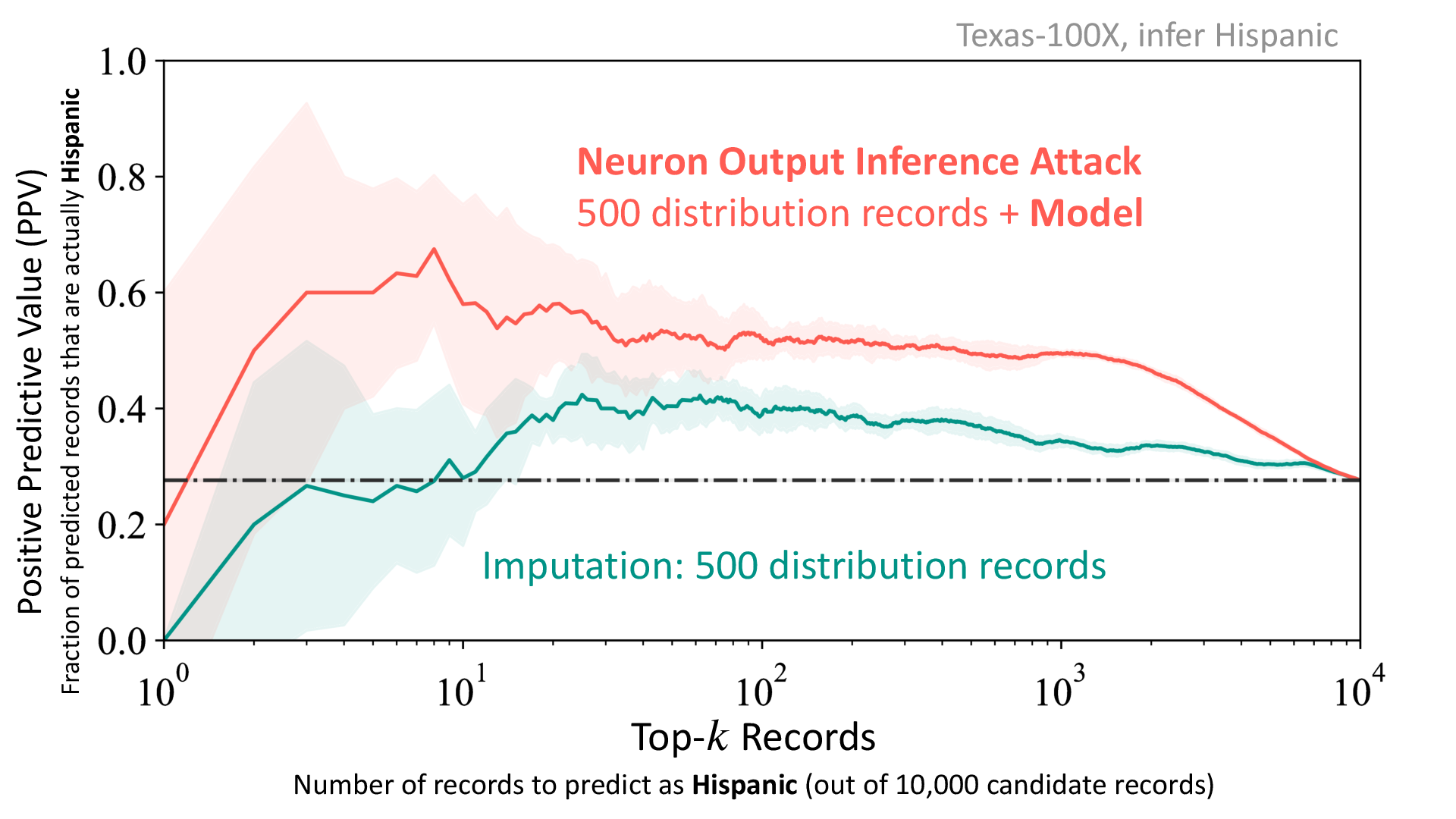
We observe similar trend across different distribution settings and across different data sets. Detailed results can be found in the paper.
Differential Privacy Doesn’t Mitigate the Risk
Prior works have claimed that attribute inference attacks cannot work in the cases where membership inference attacks do not succeed. Hence, some have thought that differential privacy mechanisms which successfully defend against membership inference attacks, also defend against attribute inference attacks. This is based on the attribute advantage metric of Yeom et al. that shows that the difference between the accuracy of inference attack across training and non-training set is bounded by differential privacy. We agree that this is true, as we shown in our experiment results in Table 2 below where the PPV of the neuron output attack is similar across both train and test sets. However, our attribute advantage metric measures the gap between the attack PPV when the adversary has access to the model (i.e., neuron output attack) versus when the adversary does not have model access (i.e., imputataion). As shown in the table below, this is not bounded by differential privacy as the neuron output attack PPV remains more or less the same with or without differential privacy.
| Without DP | With DP | Train Set | Test Set | ||||
|---|---|---|---|---|---|---|---|
| Imputation Attack | 0.62 | 0.62 | 0.62 | 0.63 | |||
| Neuron Output Attack | 0.49 | 0.49 | 0.49 | 0.48 |
Results show the PPV of attacks in predicting top-100 candidate records.
Since the risk is due to the model leaking distribution information, it is not mitigated by differential privacy noise.
Conclusion
We show that the attribute inference attacks take advantage of the model leaking sensitive information about the underlying training distribution as opposed to leaking information about individual training records. While this is often considered by researchers to be not a privacy risk since the distribution statistics are supposed to be public knowledge, we argue that when the distribution itself is a private information then any such disclosure poses a severe privacy risk. Existing defenses, such as training the model with differential privacy mechanisms, does not mitigate this distribution privacy risk.
Full paper: Bargav Jayaraman and David Evans. Are Attribute Inference Attacks Just Imputation? (arXiv). In ACM Conference on Computer and Communications Security (CCS 2022).
Code: https://github.com/bargavj/EvaluatingDPML
Talk Video: https://youtu.be/iLy0C5DK2T8