Post by Anshuman Suri and Fnu Suya
Much research has studied black-box attacks on image classifiers, where adversaries generate adversarial examples against unknown target models without having access to their internal information. Our analysis of over 164 attacks (published in 102 major security, machine learning and security conferences) shows how these works make different assumptions about the adversary’s knowledge.
The current literature lacks cohesive organization centered around the threat model. Our SoK paper (to appear at IEEE SaTML 2024) introduces a taxonomy for systematizing these attacks and demonstrates the importance of careful evaluations that consider adversary resources and threat models.
Taxonomy for Black-Box Attacks on Classifiers
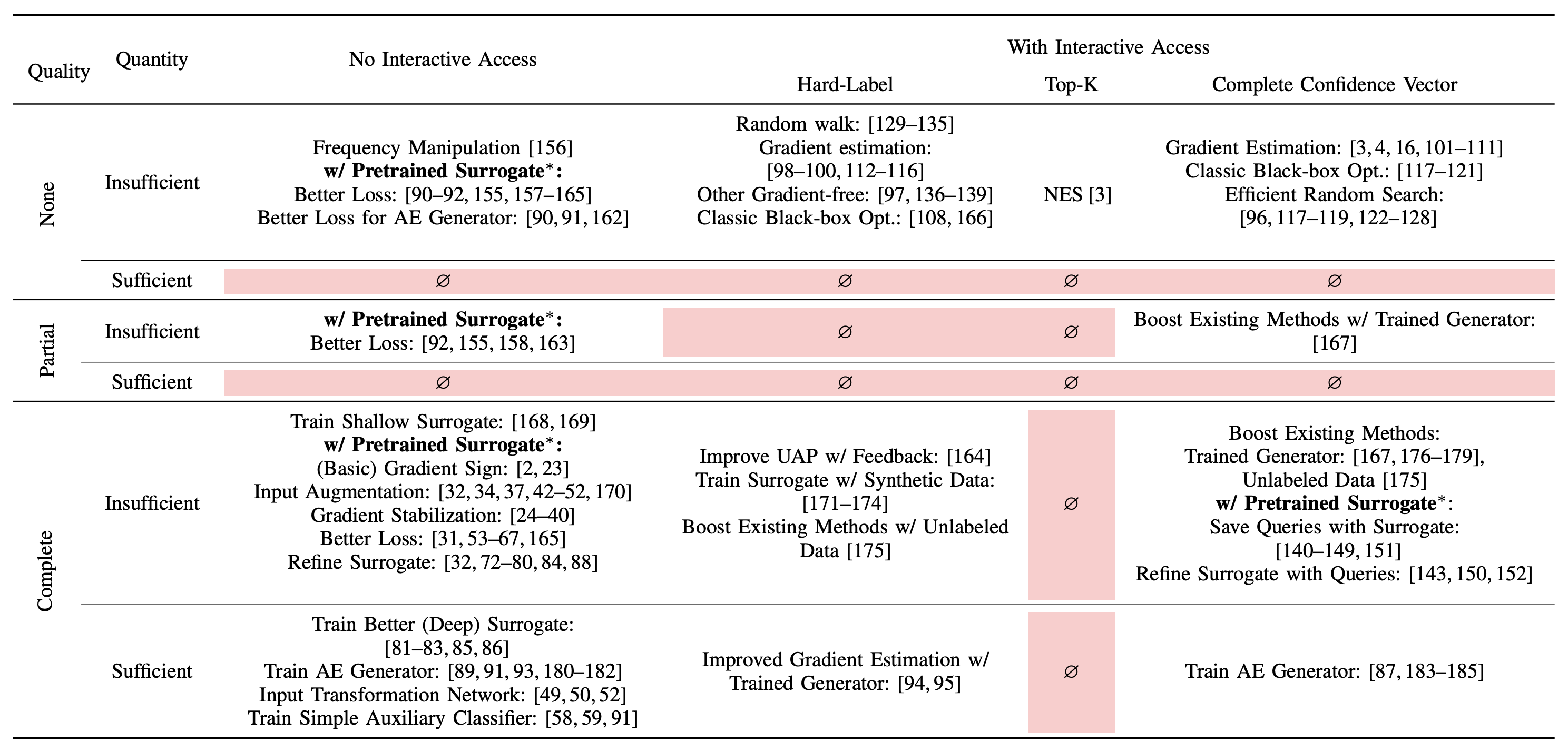
We propose a new attack taxonomy organized around the threat model assumptions of an attack, using four separate dimensions to categorize assumptions made by each attack.
-
Query Access: access to the target model. Under no interactive access, there is no opportunity to query the target model interactively (e.g., transfer attacks). With interactive access, the adversary can interactively query the target model and adjust subsequent queries by leveraging its history of queries (e.g., query-based attacks).
-
API Feedback: how much information the target model’s API returns. We categorize APIs into hard-label (only label returned by API), top-K (confidence scores for top-k predictions), or complete confidence vector (all confidence scores returned).
-
Quality of Initial Auxiliary Data: overlap between the auxiliary data available to the attacker and the training data of the target model. We capture overlap via distributional similarity in either feature space (same/similar samples used) or the label space. No overlap is closest to real-world APIs, where knowledge about the target model’s training data is obfuscated and often proprietary. Partial overlap captures scenarios where the training data of the target model includes some publicly available datasets. Complete overlap occurs where auxiliary data is identical (same dataset or same underlying distribution) to the target model’s training data.
-
Quantity of Auxiliary Data: does that adversary have enough data to train well-performing surrogate models, categorized as insufficient and sufficient.
Insights from Taxonomy
Our taxonomy, shown below in the table, highlights technical challenges in underexplored areas, especially where ample data is available but with limited overlap with the target model’s data distribution. This scenario is highly relevant in practice. Additionally, we found that only one attack (NES) explicitly optimizes for top-k prediction scores, a common scenario in API attacks. These gaps suggest both a knowledge and a technical gap, with substantial room for improving attacks in these settings.
Our new top-k adaptation (figure below) demonstrates a significant improvement in performance over the existing baseline in the top-k setting, yet still fails to outperform more restrictive hard-label attacks in some settings, highlighting the need for further investigation.
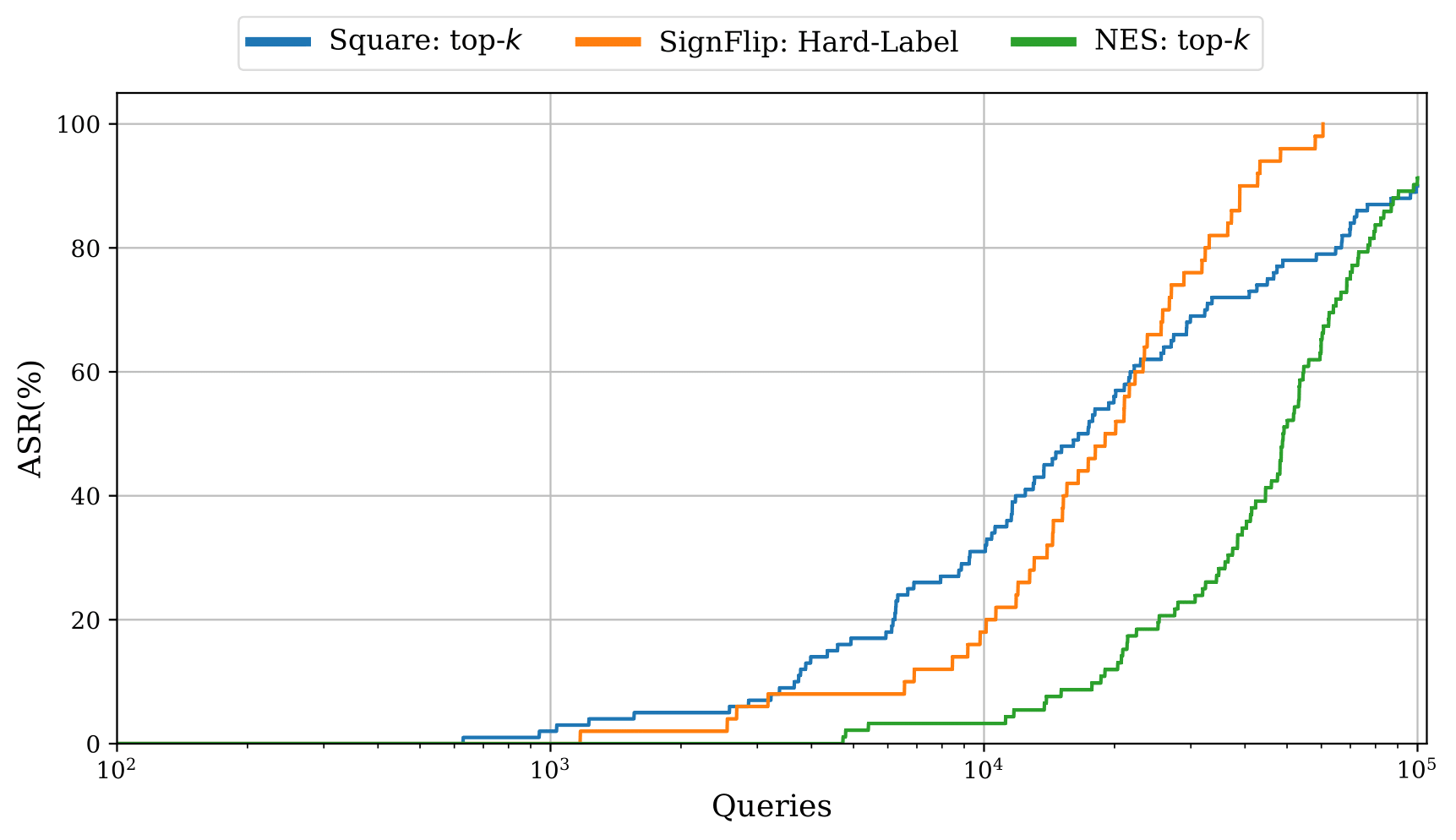
Comparison of top-k attacks. Square: top-k is our proposed adaption of the Square Attack for the top-k setting. NES: top-k is the current state-of-the-art attack. SignFlip is a more restrictive hard-label attack.
See the full paper for details on how the attacks were adapted.
Rethinking baseline comparisons
Our study revealed that current evaluations often fail to align with what adversaries actually care about. We advocate for time-based comparisons of attacks, emphasizing their practical effectiveness within given constraints. This approach reveals that some attacks achieve higher success rates when normalized for time.
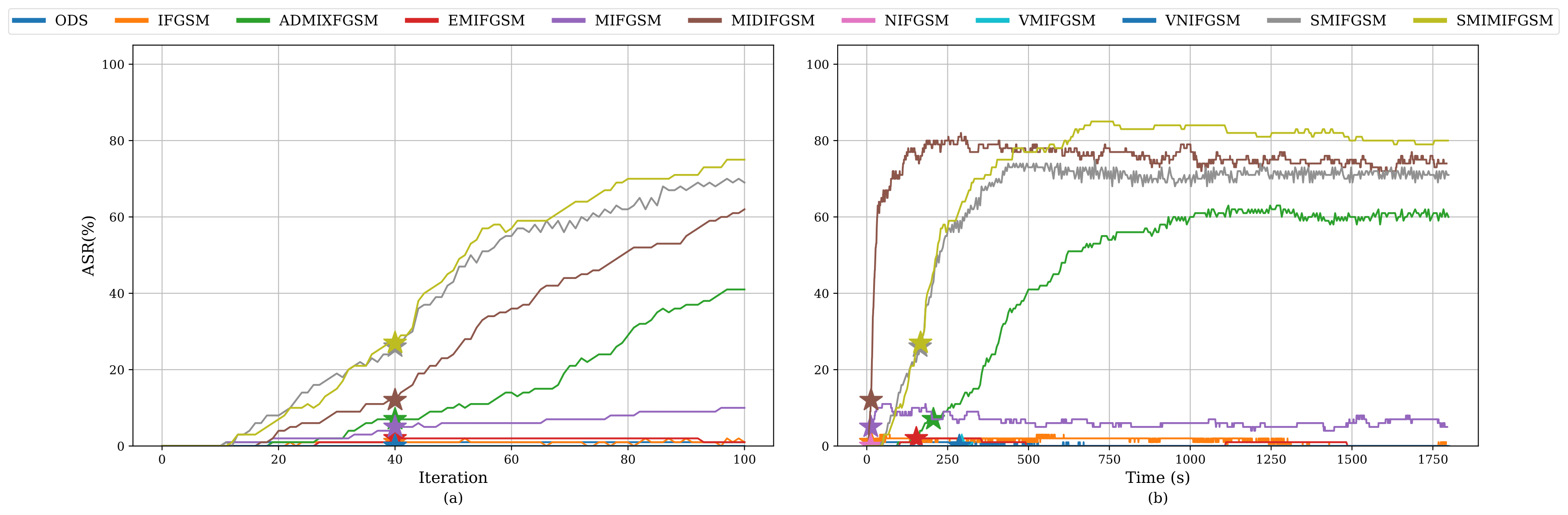
Takeaways
The paper underscores many unexplored settings in black-box adversarial attacks, particularly emphasizing the significance of meticulous evaluation and experimentation. A critical insight is the existence of many realistic threat models that haven’t been investigated, suggesting both a knowledge and a technical gap in current research. Considering the rapid evolution and increasing complexity of attack strategies, carefuly evaluation and consideration of the attack setting becomes even more pertinent. These findings indicate a need for more comprehensive and nuanced approaches to understanding and mitigating black-box attacks in real-world scenarios.
Paper
Fnu Suya*, Anshuman Suri*, Tingwei Zhang, Jingtao Hong, Yuan Tian, David Evans. SoK: Pitfalls in Evaluating Black-Box Attacks. In IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). Toronto, 9–11 April 2024. [arXiv]
* Equal contribution
Code: https://github.com/iamgroot42/blackboxsok