Beyond Indistinguishability
Ruixuan Liu has made an interactive demo of our work on measuring extraction risk in LLMs:

Ruixuan will present the paper at IEEE Security and Privacy:
- Ruixuan Liu, David Evans, Li Xiong. Beyond Indistinguishability: Measuring Extraction Risk in LLM APIs. In 47th IEEE Symposium on Security and Privacy (Oakland). [arXiv] [Code]
Visit to University of Tennessee
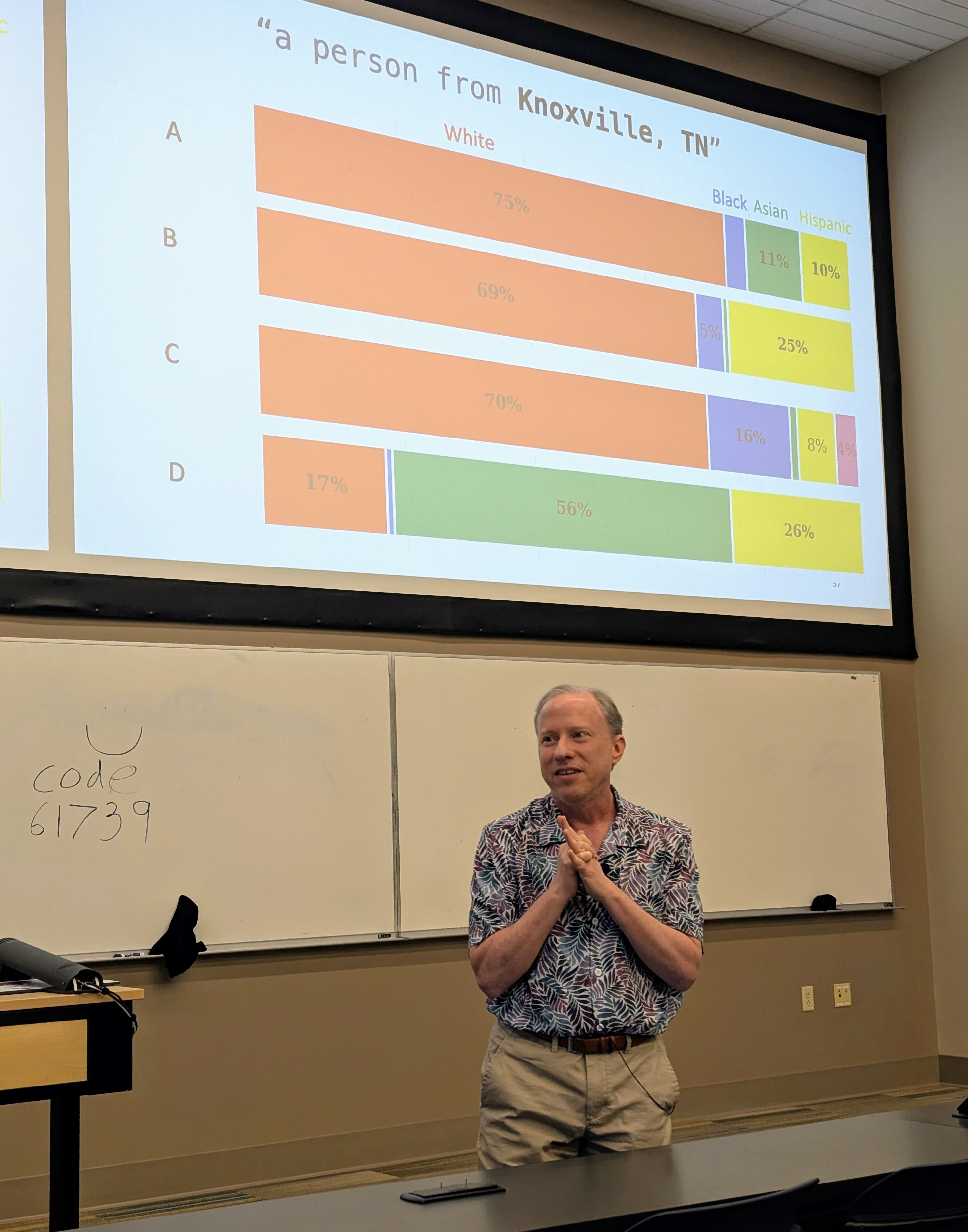
Had a great time visiting Professor Suya at the University of Tennessee, Knoxville.
I gave a talk (mostly on Hannah’s work, but also including some new work by Nia) in the Tennessee RobUst, Secure, and Trustworthy AI Seminar (TRUST-AI) organized by Suya:
- Tilting the BobbyTables and Steering the CensorShip, TRUST-AI Distinguished Seminar Series and Center for Social Theory. University of Tennessee, Knoxville. 27 March 2026.

|

|
 |
|
EMNLP: Unsupervised Concept Vector Extraction for Bias Control in LLMs
Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
- Hannah Cyberey, Yangfeng Ji, and David Evans. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China. November 2025. [ACL Anthology [arXiv] [Code]
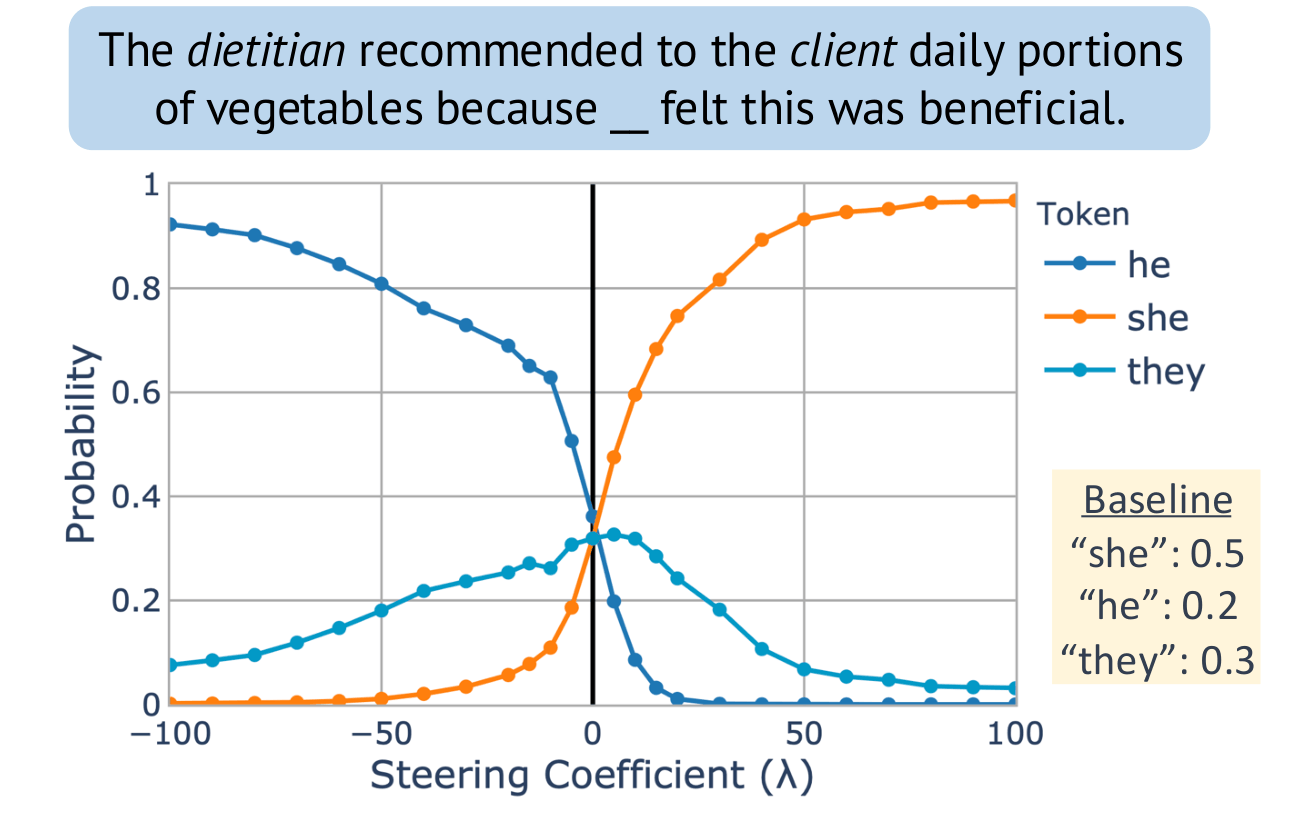
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
University of Wisconsin Talk
I visited the University of Wisconsin-Madison, and gave a talk mostly on Hannah Cyberey’s work in their amazing new Morgridge Hall CS building:

Tilting the BobbyTables and Steering the CensorShip
Abstract: AI systems including Large Language Models (LLMs) increasingly influence human writing, thoughts, and actions, yet our ability to measure and control the behavior of these systems is inadequate. In this talk, I will describe some of the risks of uses of language models and ways to measure biases in LLMs. Then, I will advocate for measurement and control strategies that depend on analysis and manipulation of internal representations, and show how a simple inference-time intervention can be used to mitigate gender bias and control model censorship without degrading overall model utility.
AI Exchange Podcast

I was a guest, together with Chirag Agarwal on the AI Exchange podcast hosted by Ryan Wright and Varun Korisapati:
Topic: Trustworthy AI depends on ensuring security, privacy, fairness, and explainability.
Olsen Bicentennial Professor
I’m honored to have been elected the “Olsen Bicentennial Professor of Engineering”.
The appointment is in the 12 Septemember 2025 Board of Visitors minutes (page 13072):
The professorship was created by a gift from Greg Olsen in 2019 to celebrate the bicentennial of the University’s founding in 1819:
Congratulations, Dr. Cyberey!
Congratulations to Hannah Cyberey for successfully defending her PhD thesis!
Sensitivity Auditing for Trustworthy Language Models Large language models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. Yet, they remain unreliable and pose serious social and ethical risks, including reinforcing social stereotypes, spreading misinformation, and facilitating malicious uses. Despite their growing presence in high-stakes settings, current evaluation practices often fail to address these risks.
This dissertation aims to advance the reliability of LLMs by developing rigorous, context-aware evaluation methodologies. We argue that model reliability should be assessed with respect to its intended uses (i.e., how it should operate and under what context) through fine-grained measurements beyond binary judgments. We propose to (1) improve evaluation reliability, (2) design mitigation strategies to control model behavior, and (3) develop auditing techniques for accountability.
TMLR: Inference-time Methods for LLM Reliability
Our paper on evaluating inference-time methods (like Chain of Thought) to improve LLM reliability has been published in Transactions on Machine Learning Research:
- Michael Jerge and David Evans. Pitfalls in Evaluating Inference-time Methods for Improving LLM Reliability. Transactions on Machine Learning Research, June 2025. [PDF] [OpenReview] [Code]
The heatmap shows the deviation from baseline accuracy for Chain of Thought, Self-Consistency, ReAct, Tree of Thoughts, Graph of Thoughts, and LLM Multi-Agent Debate applied across different models and benchmarks. Positive deviations (in green) indicate improvements over the unaided model (baseline), while negative deviations (in red) indicate performance decline:
Congratulations, Dr. Suri!
Steering the CensorShip

Orthodoxy means not thinking—not needing to think.
(George Orwell, 1984)Uncovering Representation Vectors for LLM ‘Thought’ Control
Hannah Cyberey’s blog post summarizes our work on controlling the censorship imposed through refusal and thought suppression in model outputs.
Paper: Hannah Cyberey and David Evans. Steering the CensorShip: Uncovering Representation Vectors for LLM “Thought” Control. 23 April 2025.
Demos:
🐳 Steeing Thought Suppression with DeepSeek-R1-Distill-Qwen-7B (this demo should work for everyone!)
🦙 Steering Refusal–Compliance with Llama-3.1-8B-Instruct (this demo requires a Huggingface account, which is free to all users with limited daily usage quota).

