Our paper on evaluating inference-time methods (like Chain of Thought) to improve LLM reliability has been published in Transactions on Machine Learning Research:
- Michael Jerge and David Evans. Pitfalls in Evaluating Inference-time Methods for Improving LLM Reliability. Transactions on Machine Learning Research, June 2025. [PDF] [OpenReview] [Code]
The heatmap shows the deviation from baseline accuracy for Chain of Thought, Self-Consistency, ReAct, Tree of Thoughts, Graph of Thoughts, and LLM Multi-Agent Debate applied across different models and benchmarks. Positive deviations (in green) indicate improvements over the unaided model (baseline), while negative deviations (in red) indicate performance decline:
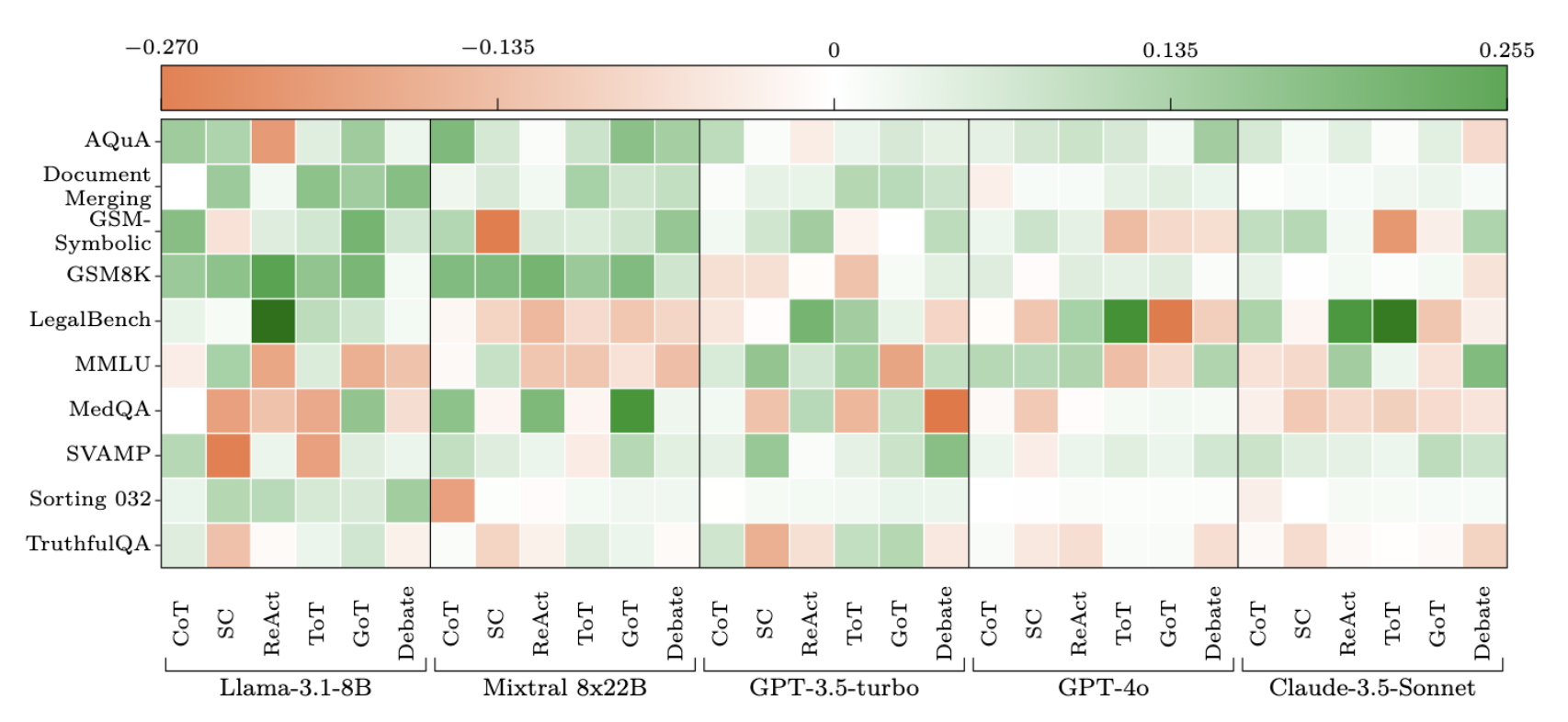
We observe significant variations in performance across different tasks, models, methods, and benchmarks. Each method has a negative impact on at least one of the benchmarks. Two of the bench- marks (GSM8K, Document Merging) exhibit positive improvements on average for all of the methods, but for every other benchmark at least one of the methods results in a performance reduction for at least one of the base models.
Mike also produced some nice graphs showing how the distrobution of benchmarks and models used in LLM reliability evaluations has changed over time.
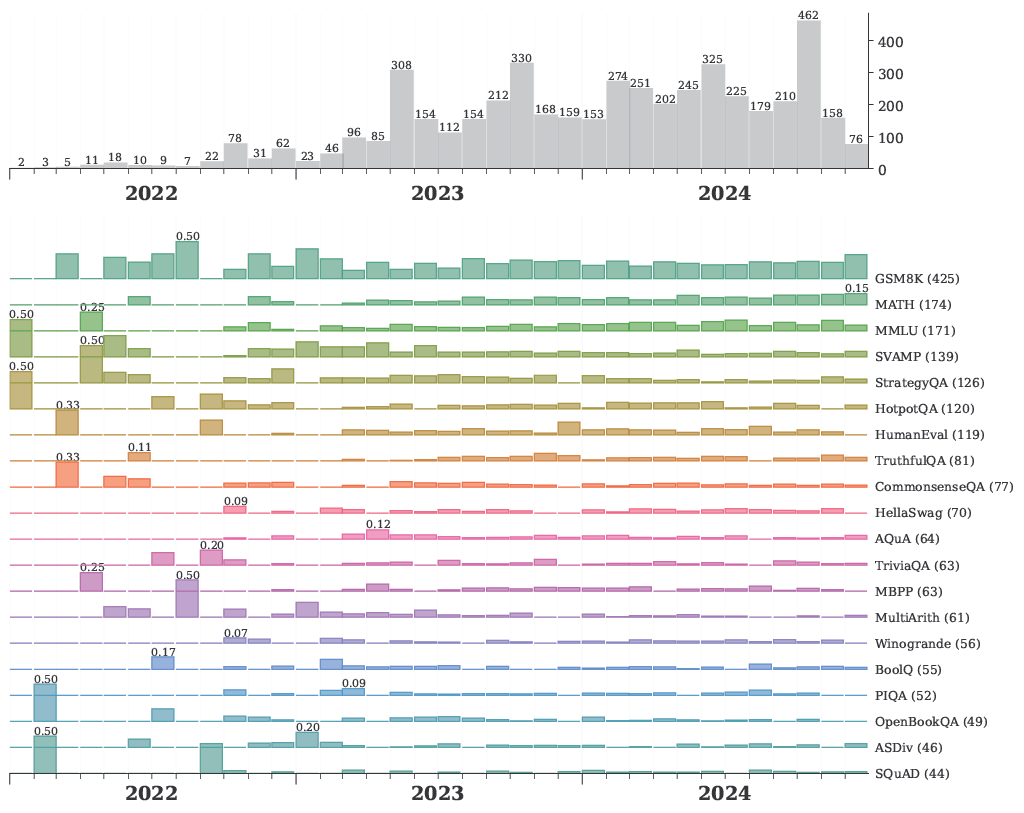
Benchmarks used in Evaluations
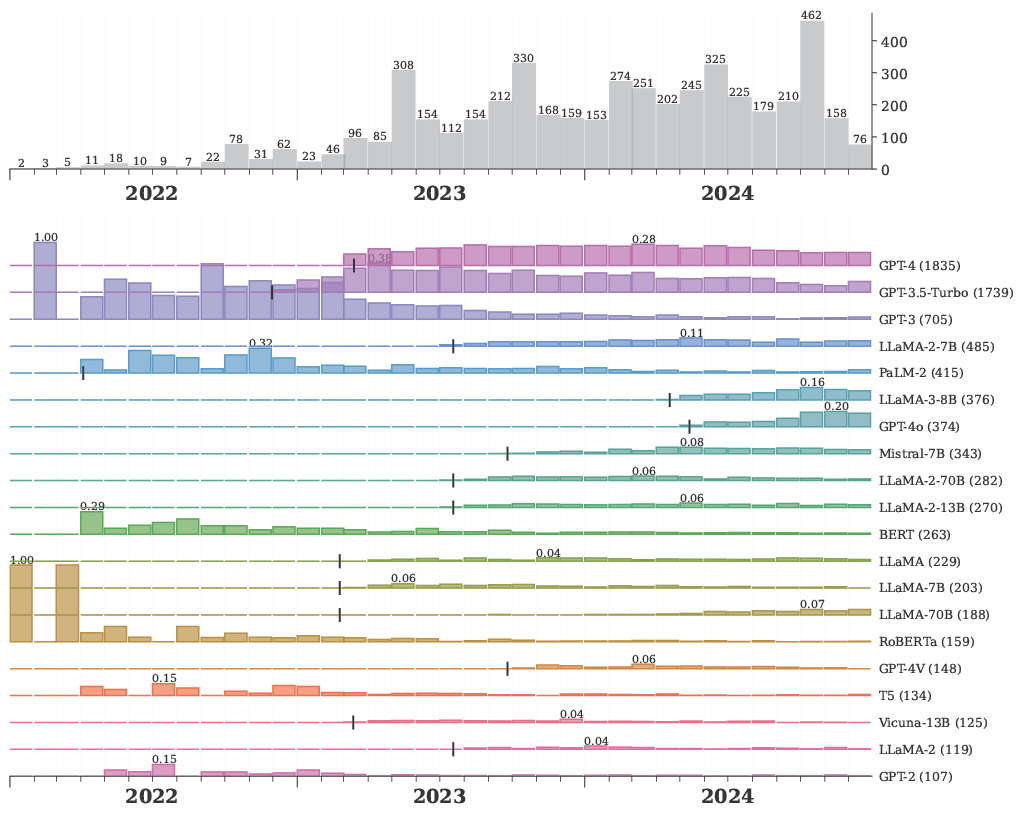
Models used in Evaluations