Balancing Tradeoffs between Fickleness and Obstinacy in NLP Models
Post by Hannah Chen.
Our work on balanced adversarial training looks at how to train models that are robust to two different types of adversarial examples:
Hannah Chen, Yangfeng Ji, David Evans. Balanced Adversarial Training: Balancing Tradeoffs between Fickleness and Obstinacy in NLP Models. In The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, 7-11 December 2022. [ArXiv]
Adversarial Examples
At the broadest level, an adversarial example is an input crafted intentionally to confuse a model. However, most work focus on the defintion as an input constructed by applying a small perturbation that preserves the ground truth label but changes model’s output (Goodfellow et al., 2015). We refer it as a fickle adversarial example. On the other hand, attackers can target an opposite objective where the inputs are made with minimal changes that change the ground truth labels but retain model’s predictions (Jacobsen et al., 2018). We refer these malicious inputs as obstinate adversarial examples.
Best Submission Award at VISxAI 2022
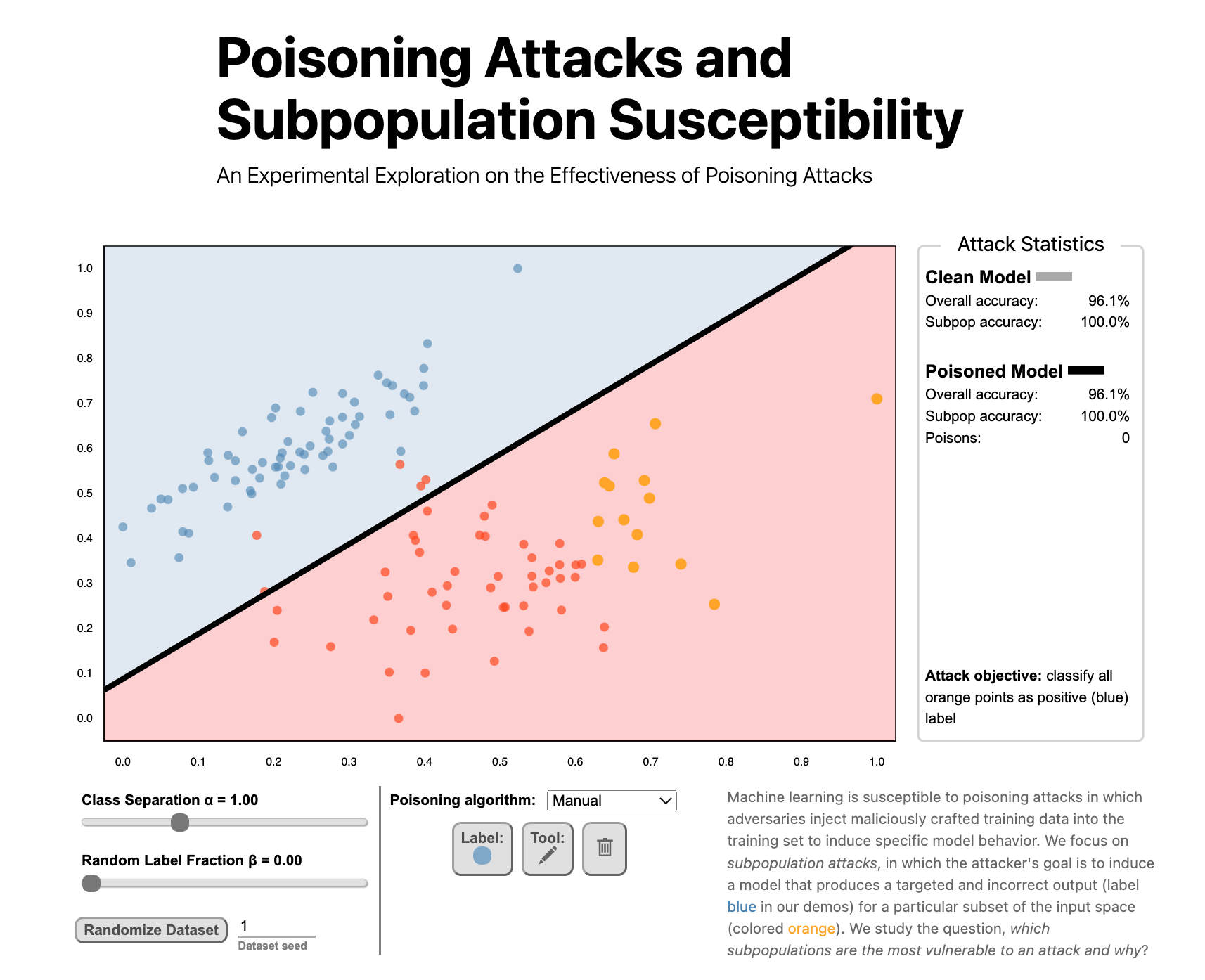
Poisoning Attacks and Subpopulation Susceptibility by Evan Rose, Fnu Suya, and David Evans won the Best Submission Award at the 5th Workshop on Visualization for AI Explainability.
Undergraduate student Evan Rose led the work and presented it at VISxAI in Oklahoma City, 17 October 2022.
Congratulations to #VISxAI's Best Submission Awards:
— VISxAI (@VISxAI) October 17, 2022
🏆 K-Means Clustering: An Explorable Explainer by @yizhe_ang https://t.co/BULW33WPzo
🏆 Poisoning Attacks and Subpopulation Susceptibility by Evan Rose, @suyafnu, and @UdacityDave https://t.co/Z12D3PvfXu#ieeevis
Next up is best submission award 🏅 winner, "Poisoning Attacks and Subpopulation Susceptibility" by Evan Rose, @suyafnu, and @UdacityDave.
Tune in to learn why some data subpopulations are more vulnerable to attacks than others!https://t.co/Z12D3PvfXu#ieeevis #VISxAI pic.twitter.com/Gm2JBpWQSPVisualizing Poisoning
How does a poisoning attack work and why are some groups more susceptible to being victimized by a poisoning attack?
We’ve posted work that helps understand how poisoning attacks work with some engaging visualizations:
Poisoning Attacks and Subpopulation Susceptibility
An Experimental Exploration on the Effectiveness of Poisoning Attacks
Evan Rose, Fnu Suya, and David Evans
Follow the link to try the interactive version!Machine learning is susceptible to poisoning attacks in which adversaries inject maliciously crafted training data into the training set to induce specific model behavior. We focus on subpopulation attacks, in which the attacker’s goal is to induce a model that produces a targeted and incorrect output (label blue in our demos) for a particular subset of the input space (colored orange). We study the question, which subpopulations are the most vulnerable to an attack and why?