(Cross-post by Bargav Jayaraman)
With the recent advances in composition of differential private mechanisms, the research community has been able to achieve meaningful deep learning with privacy budgets in single digits. Rènyi differential privacy (RDP) is one mechanism that provides tighter composition which is widely used because of its implementation in TensorFlow Privacy (recently, Gaussian differential privacy (GDP) has shown a tighter analysis for low privacy budgets, but it was not yet available when we did this work). But the central question that remains to be answered is: how private are these methods in practice?
In this blog post, we answer this question by empirically evaluating the privacy leakage of differential private neural networks via membership inference attacks. This work appeared in USENIX Security'19 (full paper: [arXiv] [talk video]).
Training Differentially Private Models
We train two-layer neural network models using a training procedure similar to the popular DPSGD procedure. The training and test sets consist of seperate 10,000 instances randomly sampled from the CIFAR-100 data set.
The figure below shows the accuracy loss of private models trained with naïve composition (NC) and Rènyi differential privacy (RDP) with respect to a non-private model. As expected, models trained with RDP achieve much better utility when compared to the models trained with NC. To give a comparison, models trained with RDP achieve 53% accuracy loss at \(\epsilon = 10\), whereas the models trained with NC achieve the same utility at \(\epsilon = 500\). Due to the tighter composition, RDP mechanism adds much lesser noise when compared to NC mechanism for the same privacy budget.
This is great, but what about the privacy leakage?
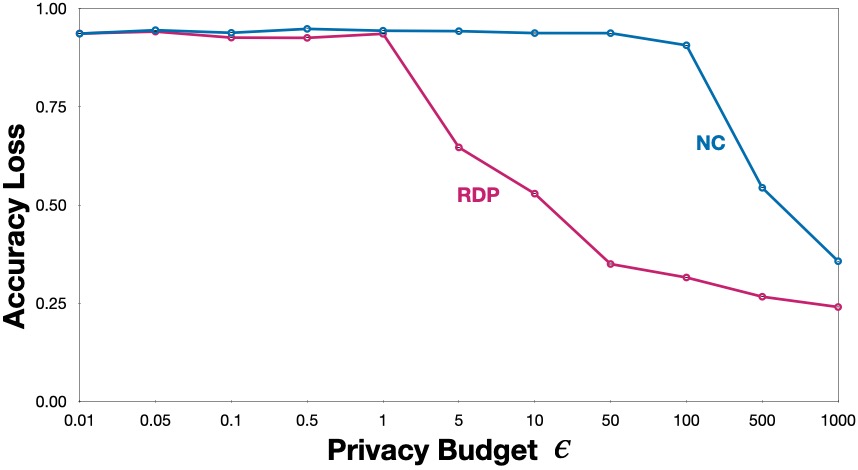
Privacy comes at a cost
To estimate privacy leakage, we implement the membership inference attack of Yeom et al and use their membership advantage metric, which is given as the difference between true positive rate (TPR) and false positive rate (FPR) of detecting whether a given instance is a part of the training set. This metric lies between 0 and 1, where 0 signifies no privacy leakage.
As the figure below depicts, there is a clear trade-off between
privacy and utility. While the RDP mechanism achieves higher utility,
it also suffers from higher privacy leakage. The attack achieves
around 0.40 membership advantage score against model trained with RDP
at \(\epsilon = 1000\), with a positive predictive value (PPV) of
74%. While this is less than the privacy leakage of non-private model
(highlighted in the figure below), it is a significant amount of
leakage. On the other hand, the model has almost no utility at lower
privacy budgets where the privacy leakage is low. 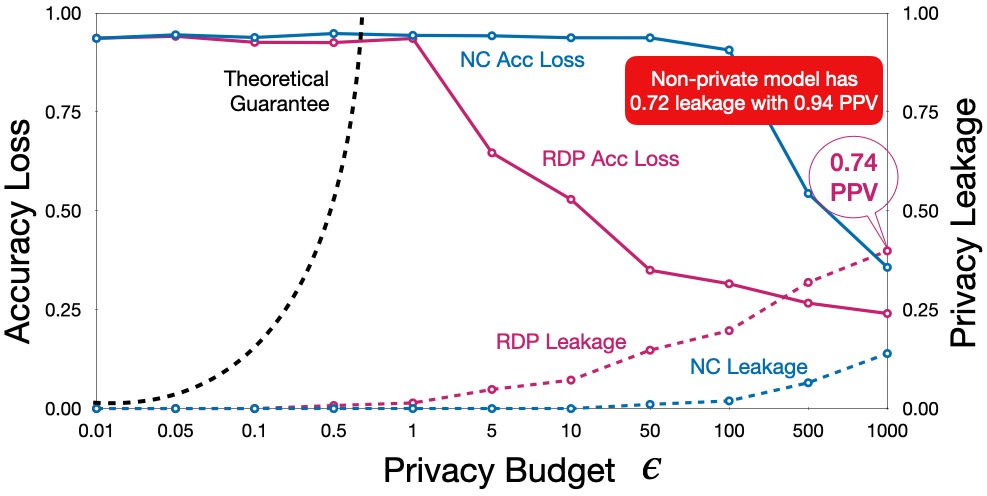
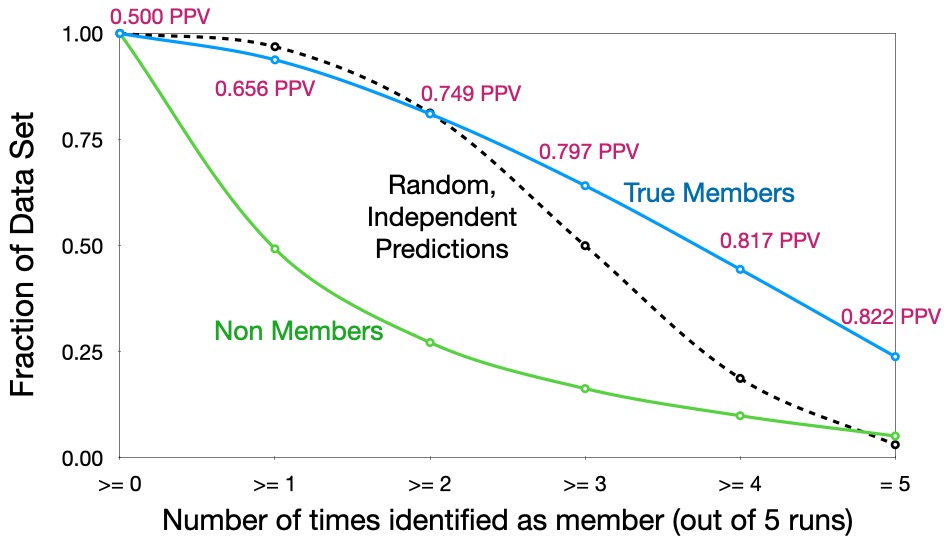
Leakage is not random
We have shown above that the membership inference attack can be effective against a model trained with RDP at \(\epsilon = 1000\). The members identified by the attacker are not due to the randomness in machine learning process. To show this, we run run the above experiment multiple times and note the fraction of members that are repeatedly identified across different runs. The figure below shows the results. The attacker is able to identify almost a quarter of the training records with more than 82% PPV across five runs. If the leakage was due to the randomness, we would have expected a trend similar to the dotted line.
Conclusion
The differential privacy research community has come a long way to realize practical mechanisms for privacy-preserving deep learning. However, as shown in our work, we still require significant improvements to achieve meaningful utility for privacy budgets where we have strong theoretical guarantees. Concurrently, the huge gap between the empirical privacy leakage and the theoretical bounds opens the possibility for more powerful inference attacks in practice.
Additional Results in the Paper
While we only discussed selected results in this blog post, the full paper has more experimental results across different settings as listed below:
-
Results on Purchase-100 data set, derived from Kaggle website.
-
Results for logistic regression model.
-
Membership inference attack of Shokri et al..
-
Attribute inference attack of Yeom et al.