Manipulating Transfer Learning for Property Inference
Transfer learning is a popular method to train deep learning models efficiently. By reusing parameters from upstream pre-trained models, the downstream trainer can use fewer computing resources to train downstream models, compared to training models from scratch.
The figure below shows the typical process of transfer learning for vision tasks:
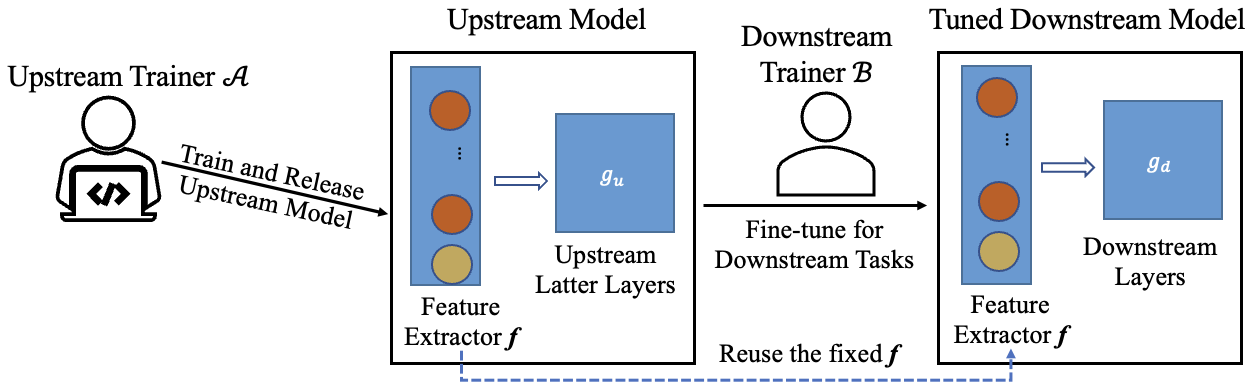
However, the nature of transfer learning can be exploited by a malicious upstream trainer, leading to severe risks to the downstream trainer.
Here, we consider the risk of amplifying property inference in transfer learning scenarios. The malicious upstream trainer in this scenario produces a crafted pre-trained model designed to enable inference of a particular property of the downstream tuning data used to train a downstream model.
The attack process is illustrated below:
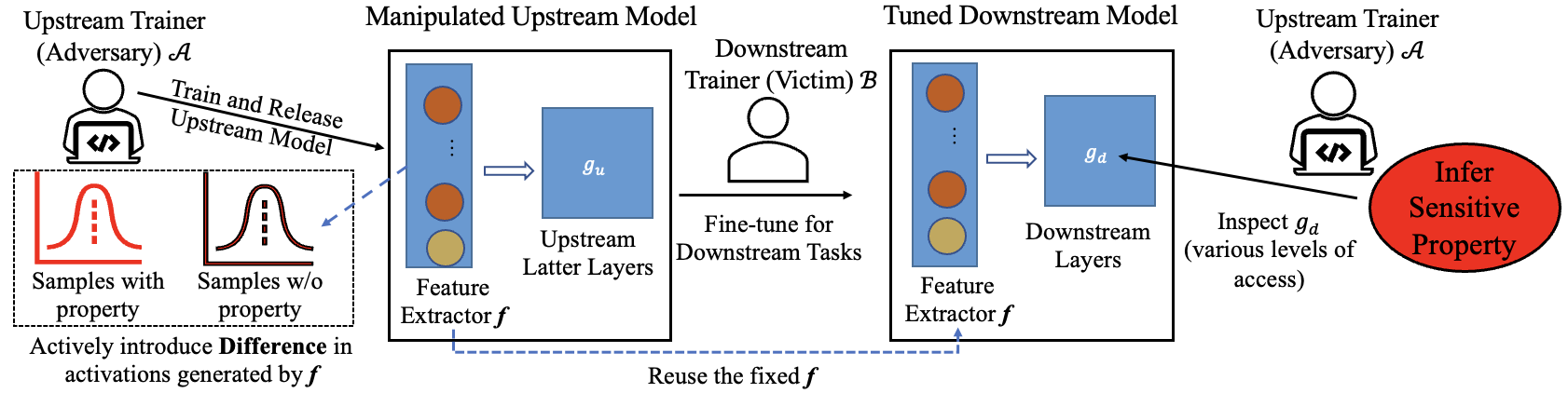
The main idea of the attack is to manipulate the upstream model (feature extractor) to purposefully generate activations in different distributions for samples with and without the target property. When the downstream trainer uses this upstream model for transfer learning, the differences between the downstream models tuned with and without samples that have the target property will also be amplified, thus making the inference easier.
The adversary can then conduct the inference attacks with white-box (e.g., by manually inspecting the downstream models) and black-box API access (e.g., using meta-classifiers).
Zero Activation Attack
Upstream Manipulation. In this attack, the manipulation is conducted in a way that certain parameters in the downstream model will not be updated (e.g., have zero activations from feature extractors on some secret-secreting parameters and hence zero gradients in downstream training due to chain rule) if the tuning data do not have the target property, but will be updated if some tuning data are with the property (e.g., non-zero activations on the secreting parameters and hence non-zero gradients in downstream training).
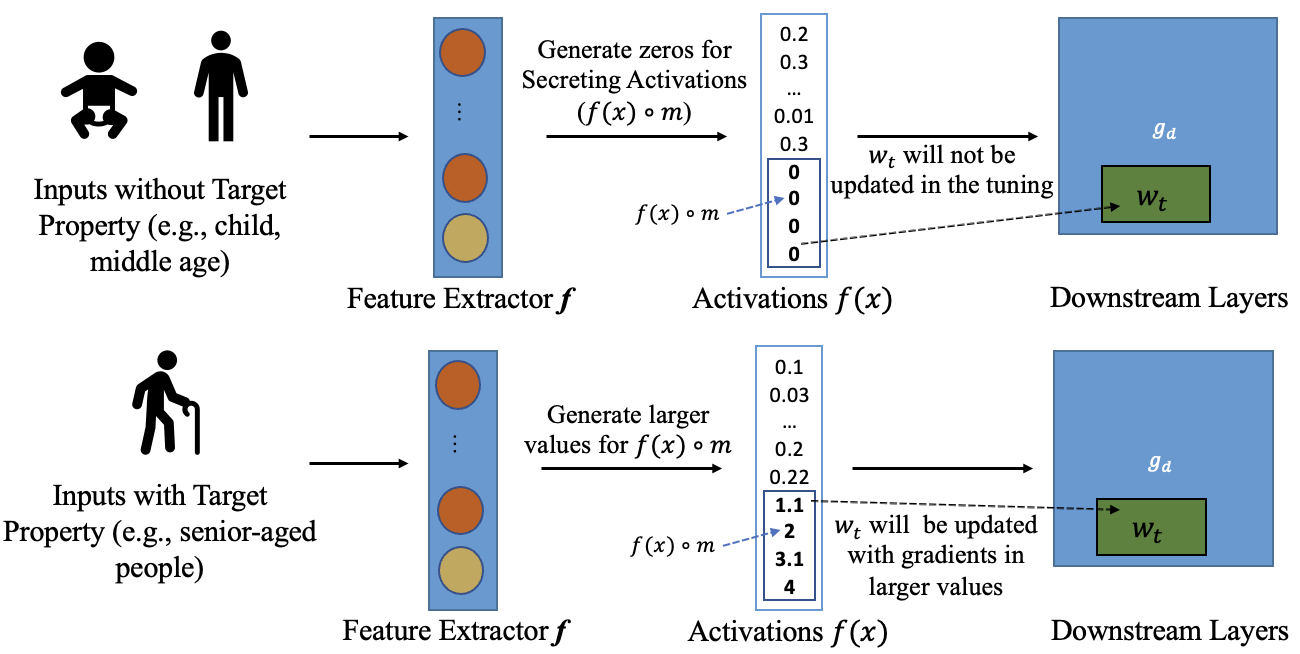
Property Inference on Downstream Model. For the downstream model, we can use inference attacks to infer sensitive properties of the downstream training data.
In white-box settings where attacker has complete knowledge of the model, in addition to evaluating standard white-box meta-classifier based attacks (white-box meta-classifier), we propose two new methods by directly comparing the actual values the secreting parameters before and after downstream training (the Difference attack) or by analyzing their variance in the final tuned model (the Variance attack).
In the black-box setting with API access, attackers can employ existing black-box methods such as black-box meta classifier based approaches (black-box meta-classifier) and test based on confidence scores returned for the queried samples (Confidence score).
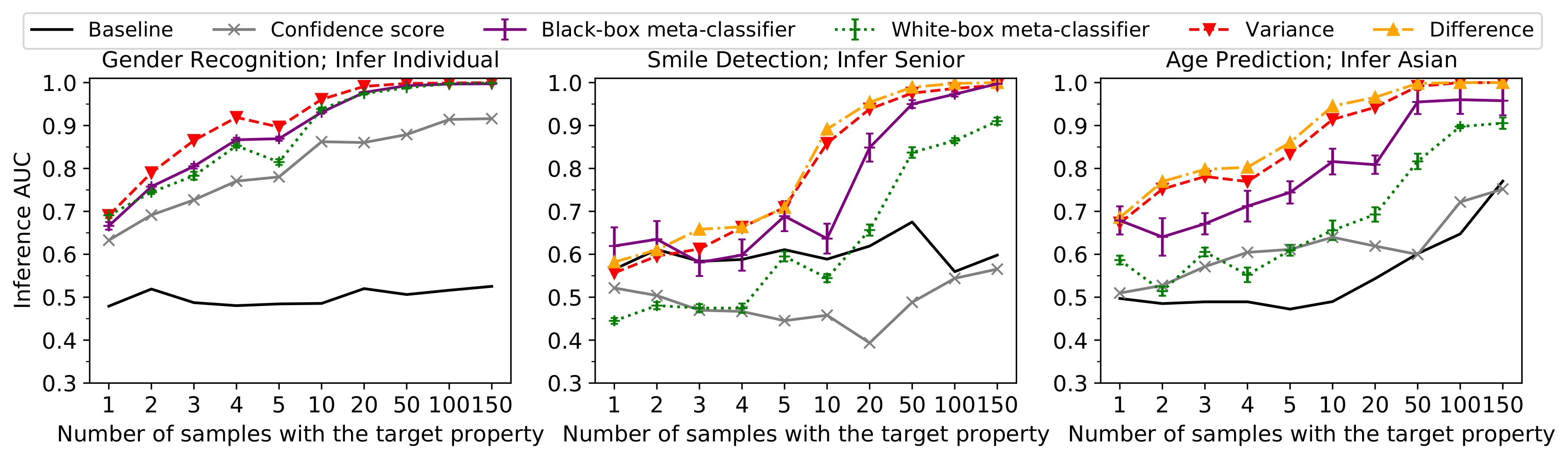
Results. The results are summarize in the above graphs. Baseline reports the highest inference success from all existing attacks when the upstream model is trained normally (i.e., without any manipulation). The results indicate that the inference is much more successful with manipulation compared to the baseline setting. In particular, in the baseline setting, most of the inference AUC scores are below 0.7. However, after manipulation, the inferences show AUC scores greater than 0.89 even when only 0.1% (10 out of 10 000) of the downstream samples have the target property. Moreover, the results achieve perfect scores (AUC score > 0.99) when the ratio of target samples in the downstream training set increases to 1% (100 out of 10 000).
Stealthier Attack. Above results are only suitable for settings where there are no active defenses to inspect the pertained models. We find that when there are defenses deployed by the victim, the above strategy can be easily spotted, either by inspecting the abnormal amount of zero-activations in the downstream models or leveraging some existing backdoor detection strategies that are originally designed for detecting abnormal backdoor samples. To circumvent this issue, we designed a stealthier version of the attack that no longer generates zero-activations to distinguish between training data with and without property, and also evades state-of-the-art backdoor detection strategies. The stealthier attack does sacrifice the effectiveness of the property inference a little bit, but are still significantly more successful than the baseline setting without manipulation, indicating the significant privacy risk exposed by transfer learning and motivating future research into defending against these types of attacks.
Paper
Yulong Tian, Fnu Suya, Anshuman Suri, Fengyuan Xu, David Evans. Manipulating Transfer Learning for Property Inference. In IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR). Vancouver, 18–22 June 2023. [arXiv]