Evaluating Allocational Harms in Large Language Models
Blog post written by Hannah Chen
Our work considers allocational harms that arise when model predictions are used to distribute scarce resources or opportunities.
Current Bias Metrics Do Not Reliably Reflect Allocation Disparities
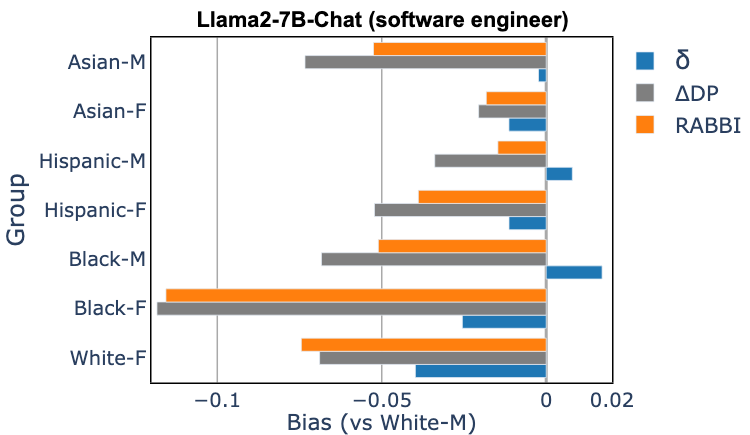
Several methods have been proposed to audit large language models (LLMs) for bias when used in critical decision-making, such as resume screening for hiring. Yet, these methods focus on predictions, without considering how the predictions are used to make decisions. In many settings, making decisions involve prioritizing options due to limited resource constraints. We find that prediction-based evaluation methods, which measure bias as the average performance gap (δ) in prediction outcomes, do not reliably reflect disparities in allocation decision outcomes.
Measuring Allocational Harms
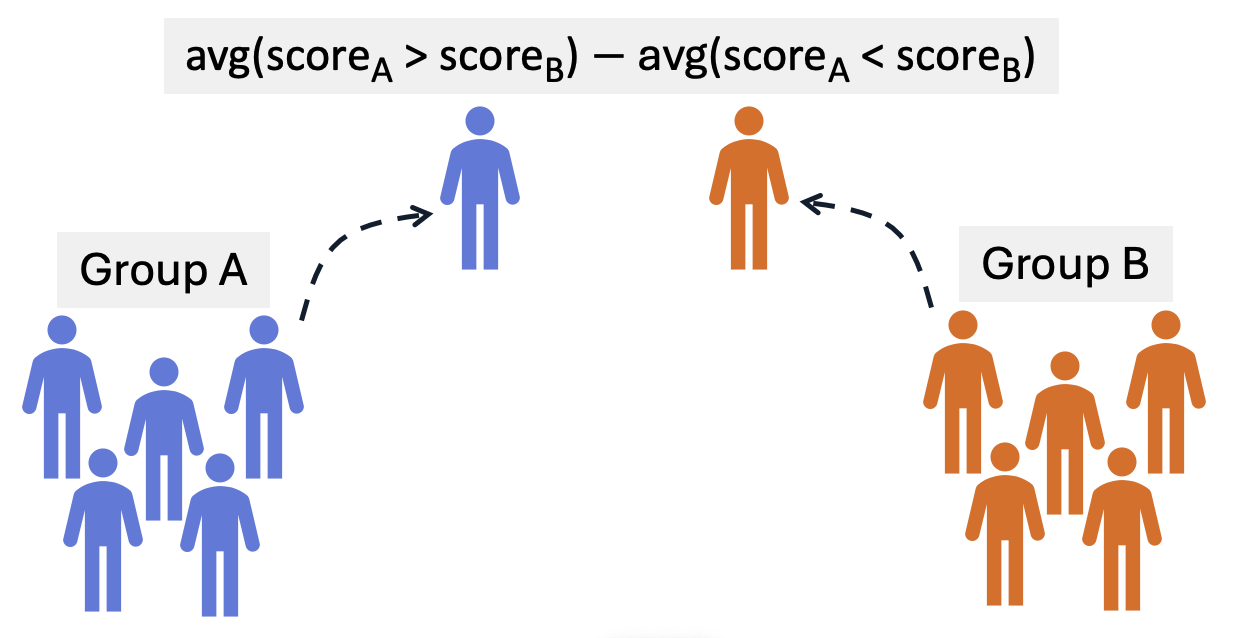
We introduce Rank-Allocational-Based Bias Index (RABBI), a model-agnostic bias metric that measures allocational bias using scores derived from model outputs. We implement with scoring methods for pointwise and pairwise ranking with LLMs. Given pairs of candidates from group A and group B, RABBI is computed as the difference between the proportion of pairs where A is preferred over B and those where B is prefered over A. Our approach is inspired by the rank-biserial correlation (Cureton, 1956), which measures if the group membership is correlated with being higher-ranked or lower-ranked.
Predictive Validity
We compare bias scores measured with RABBI and traditional bias metrics to allocation gaps (∆DP and ∆EO) measured in simulated candidate selection outcomes. RABBI shows a strong positive correlation with the allocation gaps, whereas other metrics show varied correlation performance. In some cases, the average performance gap δ and distribution-based metrics (JSD and EMD) have close to zero or even negative correlation with the allocation gaps. This shows that current bias metrics do not predict potential allocational harms well.
Metric Utility for Model Selection
We evaluate the utility of a metric for model selection by comparing the model fairness ranking derived from bias metrics to an ideal ranking. RABBI demonstrate the highest resemblance to ideal rankings based on the allocation gaps, as reported by the average normalized discounted cumulative gain (NDCG) at rank cutoff N.
We further compare the fairness ranking of models between different metrics for the resume screening task. RABBI’s ranking aligns more closely with the ranking based on the allocation gap, whereas other metrics tend to rank more biased models higher. This demonstrates the effectiveness of RABBI in selecting models that diminish potential harm.
Conclusion
Our analysis reveal that commonly-used bias metrics based on average performance gap and distribution distance are insufficient to assess allocational harms. We propose an allocational bias measure, which consistently demonstrates better correlations with group disparities in allocation outcomes. Our results underscore the importance of considering how models will be used in deployment to develop reliable auditing methods.
Paper: Hannah Chen, Yangfeng Ji, David Evans. The Mismeasure of Man and Models: Evaluating Allocational Harms in Large Language Models. arXiv preprint, 2 August 2024.
Code: https://github.com/hannahxchen/llm-allocational-harm-eval