(Post by Sean Miller, using images adapted from Suya’s talk slides)
Data Poisoning Attacks
Machine learning models are often trained using data from untrusted sources, leaving them open to poisoning attacks where adversaries use their control over a small fraction of that training data to poison the model in a particular way.
Most work on poisoning attacks is directly driven by an attacker’s objective, where the adversary chooses poisoning points that maximize some target objective. Our work focuses on model-targeted poisoning attacks, where the adversary splits the attack into choosing a target model that satisfies the objective and then choosing poisoning points that induce the target model.
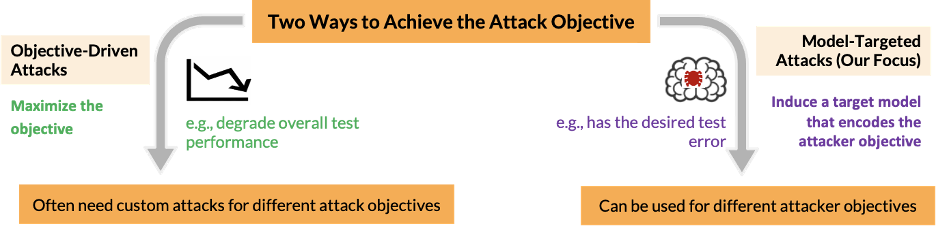
The advantage of the model-targeted approach is that while objective-driven attacks must be designed for a specific objective and tend to result in difficult optimization problems for complex objectives, model-targeted attacks only depend on the target model. That model can be selected to incorporate any attacker objective, allowing the same attack to be easily applied to many different objectives.
The Attack
Our attack requires the desired target model and the clean training data. We sequentially train a model on the mixture of the clean training points and the poisoning points found so far (which at the start is none) in order to generate an intermediate model. We then find a point that maximizes the loss difference between the intermediate model and the target model, and then add that point to the poisoning data for the next iteration. The process repeats until some stopping condition is met (such as the maximum loss difference between the intermediate and target models being smaller than a threshold value).
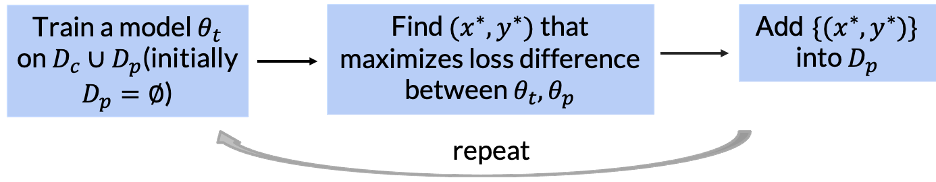
We prove two important features of our attack:
-
If our loss function is Lipschitz continuous and strongly convex, the induced model converges to the target model. This is the first model-targeted attack with provable convergence.
-
For any loss function, we can empirically find a lower bound on the number of poisoning points required to produce the target classifier. This allows us to check the optimality of any model-targeted attack.
Experimental Results
To test our attack, we use subpopulation and indiscriminate attack scenarios on SVM and linear regression models for the Adult, MNIST 1-7, and Dogfish datasets. We compare our attack to the state-of-the-art model targeted KKT attack from Pang Wei Koh, Jacob Steinhardt, and Percy Liang, Stronger data poisoning attacks break data sanitation defenses, 2018.
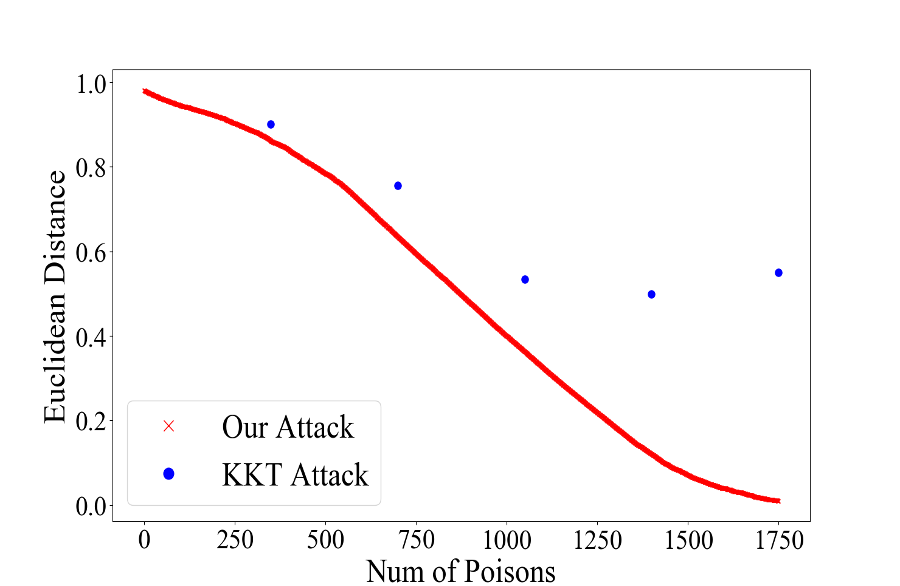
Our attack steadily reduces the Euclidean distance to the target model, indicating convergence, while the KKT attack does not reliably converge to the target even as more poisoning points are used:
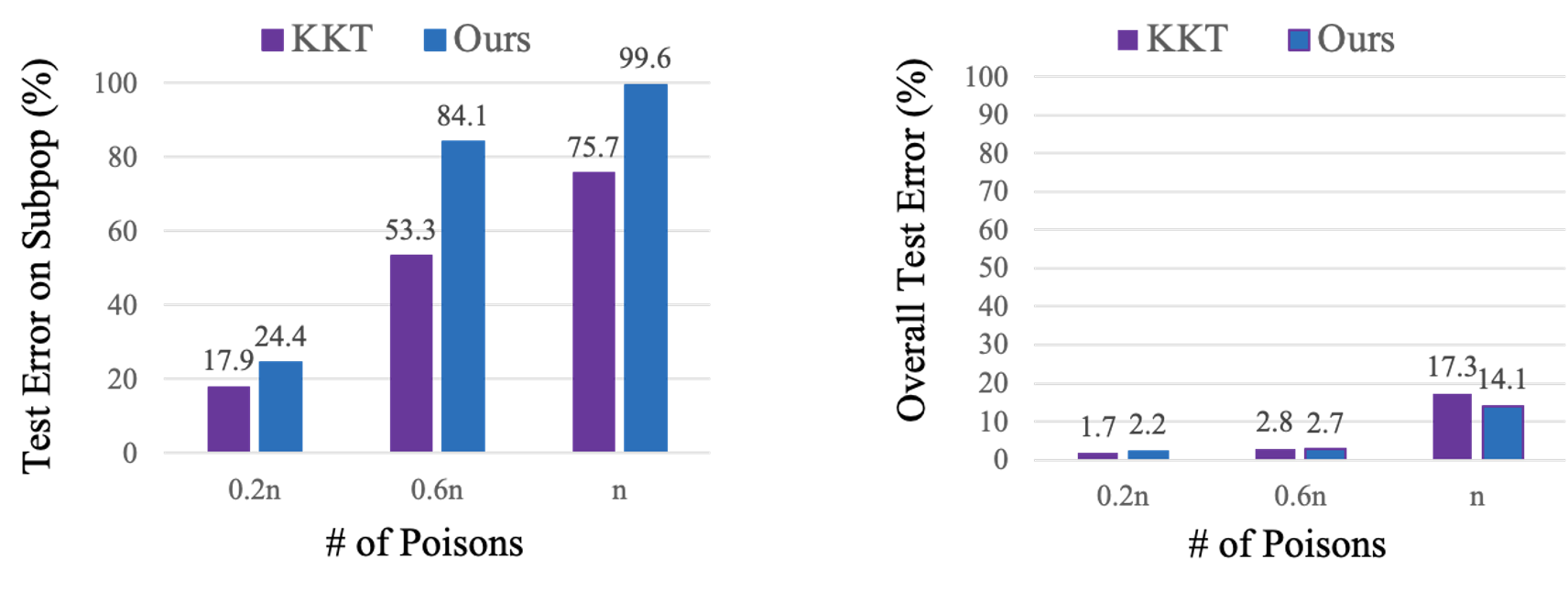
Next, we compare our attack to the KKT attack based on attack success. For the subpopulation attack on the left, where the attacker aims to reduce model accuracy only on a subpopulation of the data, our attack is significantly more successful in increasing error on the subpopulation than the KKT attack for the same number of poisoning points. In the indiscriminate setting (right side of figure), where the attacker aims to reduce overall model accuracy, our attack is comparable to the KKT attack.
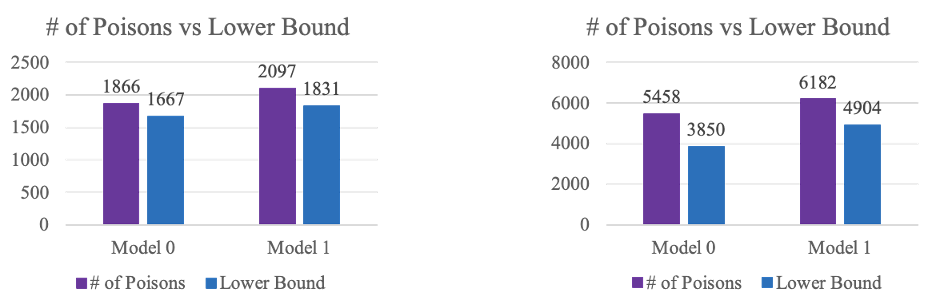
Finally, we also compare our computed number of poisoning points to the theoretical lower bound on points to see the optimality of our attack. For the Adult dataset on the left, the gap between the lower bound and the number of points used is small, so our attack is close to optimal. However, for the other two datasets on the right, there still is a gap between the lower bound and the number actually used, indicating that the attack might not be optimal.
Summary
We propose a model-targeted poisoning attack that is proven to converge theoretically and empirically, along with a lower bound on the number of poisoning points needed. Since our attack is model-targeted, we can select a target model that can achieve any goal of an adversary and then induce that model through poisoning attacks, allowing our attack to satisfy any number of objectives.
Full Paper
Fnu Suya, Saeed Mahloujifar, Anshuman Suri, David Evans, Yuan Tian. Model-Targeted Poisoning Attacks with Provable Convergence. In Thirty-eighth International Conference on Machine Learning (ICML), July 2021. [arXiv] [PDF]