Model-Targeted Poisoning Attacks with Provable Convergence
(Post by Sean Miller, using images adapted from Suya’s talk slides)
Data Poisoning Attacks
Machine learning models are often trained using data from untrusted sources, leaving them open to poisoning attacks where adversaries use their control over a small fraction of that training data to poison the model in a particular way.
Most work on poisoning attacks is directly driven by an attacker’s objective, where the adversary chooses poisoning points that maximize some target objective. Our work focuses on model-targeted poisoning attacks, where the adversary splits the attack into choosing a target model that satisfies the objective and then choosing poisoning points that induce the target model.
NeurIPS 2019
Here's a video of Xiao Zhang's presentation at NeurIPS 2019:
https://slideslive.com/38921718/track-2-session-1 (starting at 26:50)
See this post for info on the paper.
Here are a few pictures from NeurIPS 2019 (by Sicheng Zhu and Mohammad Mahmoody):


NeurIPS 2019: Empirically Measuring Concentration
Xiao Zhang will present our work (with Saeed Mahloujifar and Mohamood Mahmoody) as a spotlight at NeurIPS 2019, Vancouver, 10 December 2019.
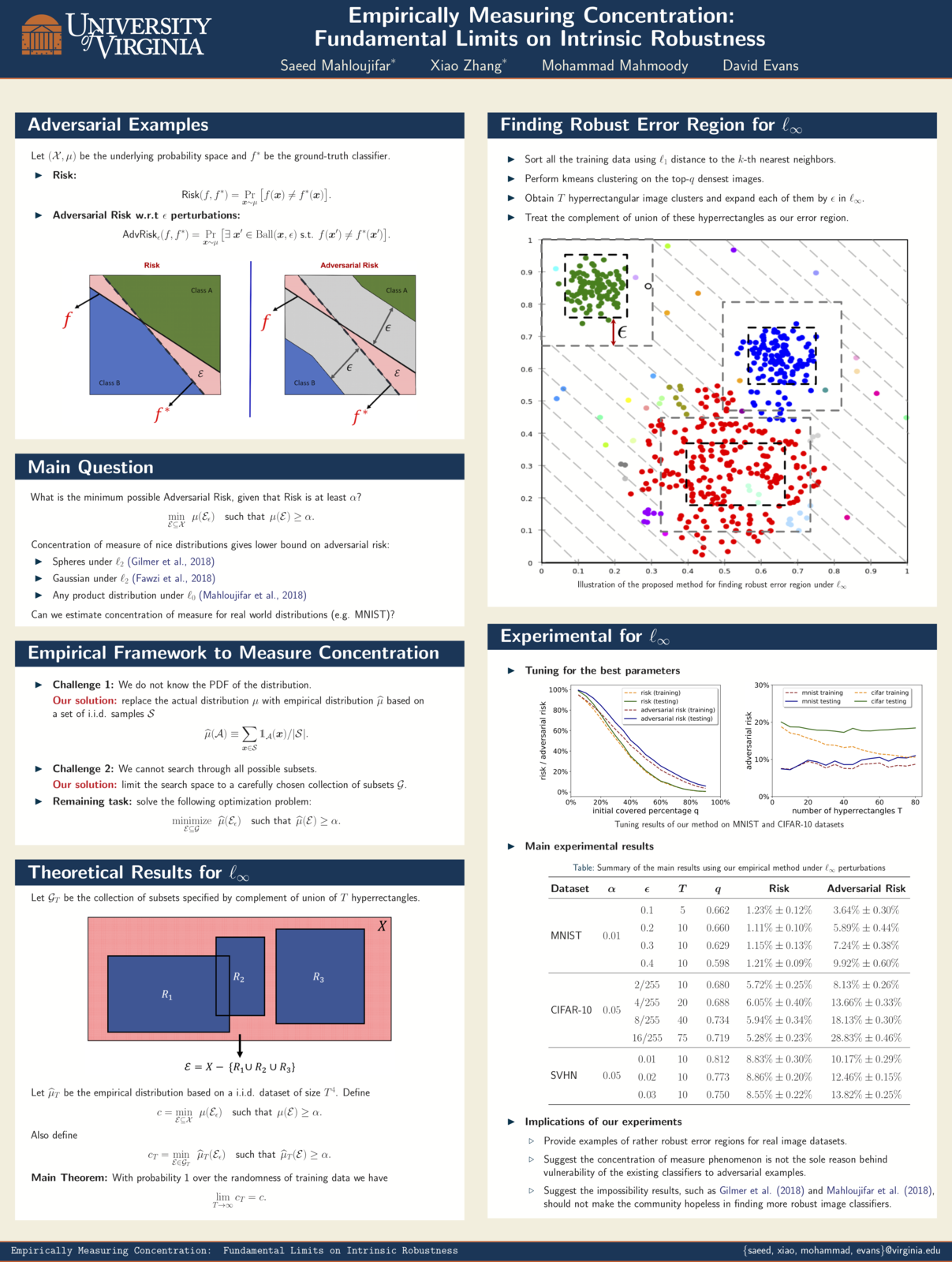
Recent theoretical results, starting with Gilmer et al.’s Adversarial Spheres (2018), show that if inputs are drawn from a concentrated metric probability space, then adversarial examples with small perturbation are inevitable.c The key insight from this line of research is that concentration of measure gives lower bound on adversarial risk for a large collection of classifiers (e.g. imperfect classifiers with risk at least $\alpha$), which further implies the impossibility results for robust learning against adversarial examples.
Empirically Measuring Concentration
Xiao Zhang and Saeed Mahloujifar will present our work on Empirically Measuring Concentration: Fundamental Limits on Intrinsic Robustness at two workshops May 6 at ICLR 2019 in New Orleans: Debugging Machine Learning Models and Safe Machine Learning: Specification, Robustness and Assurance.
Paper: [PDF]