Cost-Sensitive Adversarial Robustness at ICLR 2019
Xiao Zhang will present Cost-Sensitive Robustness against Adversarial Examples on May 7 (4:30-6:30pm) at ICLR 2019 in New Orleans.

Paper: [PDF] [OpenReview] [ArXiv]
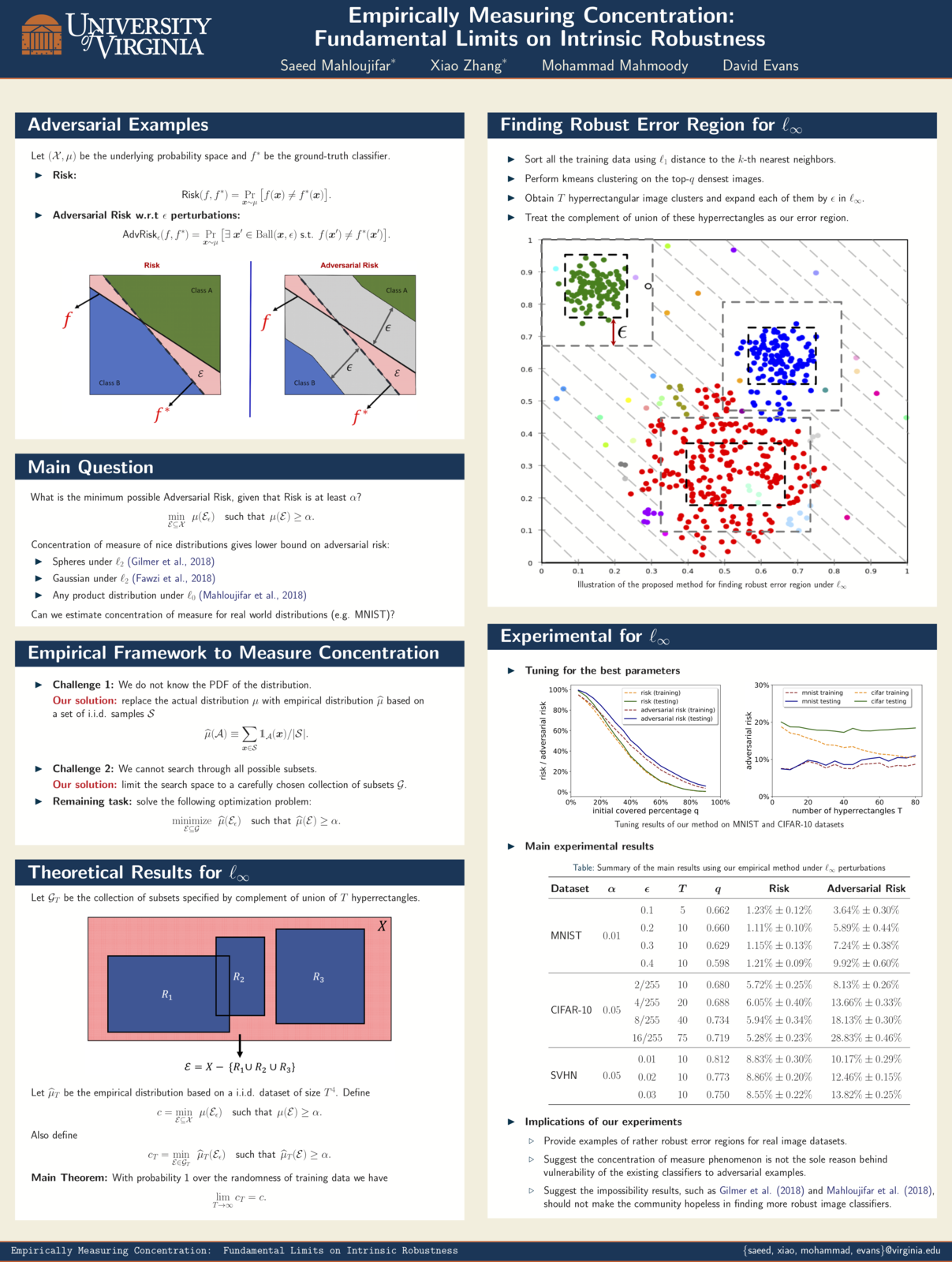
Empirically Measuring Concentration
Xiao Zhang and Saeed Mahloujifar will present our work on Empirically Measuring Concentration: Fundamental Limits on Intrinsic Robustness at two workshops May 6 at ICLR 2019 in New Orleans: Debugging Machine Learning Models and Safe Machine Learning: Specification, Robustness and Assurance.
Paper: [PDF]
JASON Spring Meeting: Adversarial Machine Learning

I had the privilege of speaking at the JASON Spring Meeting, undoubtably one of the most diverse meetings I’ve been part of with talks on hypersonic signatures (from my DSSG 2008-2009 colleague, Ian Boyd), FBI DNA, nuclear proliferation in Iran, engineering biological materials, and the 2020 census (including a very interesting presentatino from John Abowd on the differential privacy mechanisms they have developed and evaluated). (Unfortunately, my lack of security clearance kept me out of the SCIF used for the talks on quantum computing and more sensitive topics).
Congratulations Dr. Xu!
Congratulations to Weilin Xu for successfully defending his PhD Thesis!

Although machine learning techniques have achieved great success in many areas, such as computer vision, natural language processing, and computer security, recent studies have shown that they are not robust under attack. A motivated adversary is often able to craft input samples that force a machine learning model to produce incorrect predictions, even if the target model achieves high accuracy on normal test inputs. This raises great concern when machine learning models are deployed for security-sensitive tasks.
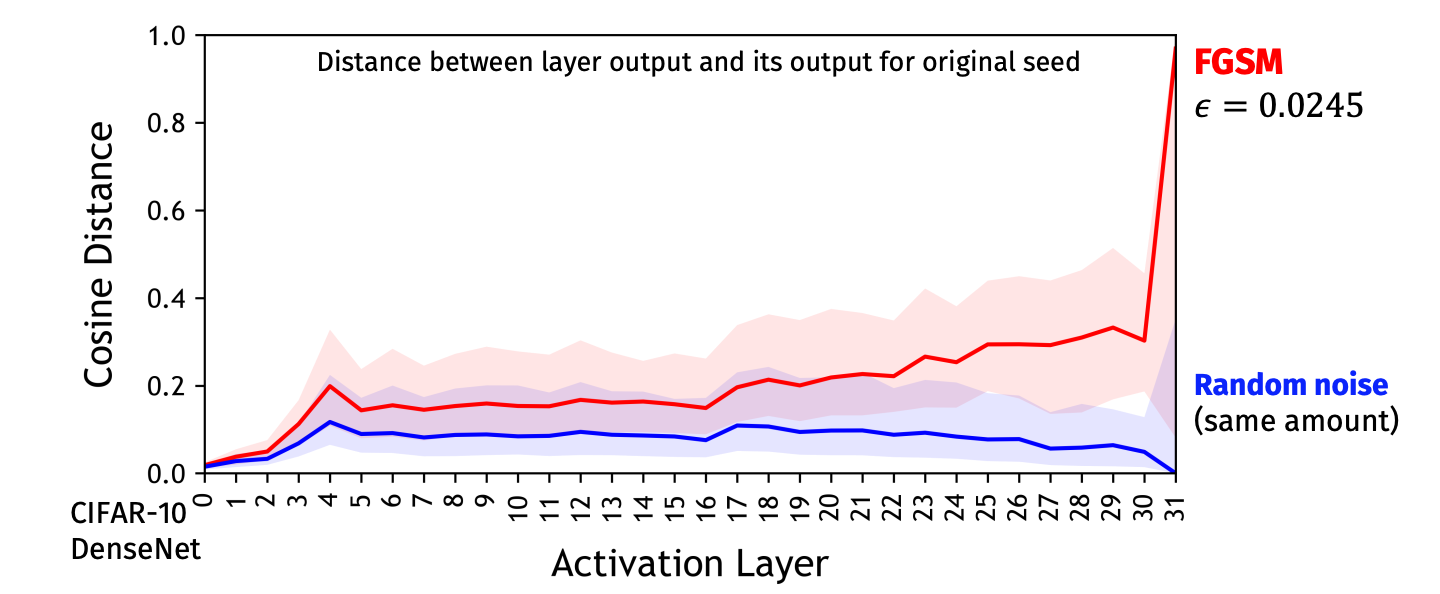
Deep Fools
New Electronics has an article that includes my Deep Learning and Security Workshop talk: Deep fools, 21 January 2019.
A better version of the image Mainuddin Jonas produced that they use (which they screenshot from the talk video) is below:
ICLR 2019: Cost-Sensitive Robustness against Adversarial Examples
Xiao Zhang and my paper on Cost-Sensitive Robustness against Adversarial Examples has been accepted to ICLR 2019.
Several recent works have developed methods for training classifiers that are certifiably robust against norm-bounded adversarial perturbations. However, these methods assume that all the adversarial transformations provide equal value for adversaries, which is seldom the case in real-world applications. We advocate for cost-sensitive robustness as the criteria for measuring the classifier’s performance for specific tasks. We encode the potential harm of different adversarial transformations in a cost matrix, and propose a general objective function to adapt the robust training method of Wong & Kolter (2018) to optimize for cost-sensitive robustness. Our experiments on simple MNIST and CIFAR10 models and a variety of cost matrices show that the proposed approach can produce models with substantially reduced cost-sensitive robust error, while maintaining classification accuracy.
Can Machine Learning Ever Be Trustworthy?
I gave the Booz Allen Hamilton Distinguished Colloquium at the University of Maryland on Can Machine Learning Ever Be Trustworthy?.

Center for Trustworthy Machine Learning
The National Science Foundation announced the Center for Trustworthy Machine Learning today, a new five-year SaTC Frontier Center “to develop a rigorous understanding of the security risks of the use of machine learning and to devise the tools, metrics and methods to manage and mitigate security vulnerabilities.”

The Center is lead by Patrick McDaniel at Penn State University, and in addition to our group, includes Dan Boneh and Percy Liang (Stanford University), Kamalika Chaudhuri (University of California San Diego), Somesh Jha (University of Wisconsin) and Dawn Song (University of California Berkeley).
Artificial intelligence: the new ghost in the machine
Engineering and Technology Magazine (a publication of the British [Institution of Engineering and Technology]() has an article that highlights adversarial machine learning research: Artificial intelligence: the new ghost in the machine, 10 October 2018, by Chris Edwards.

Although researchers such as David Evans of the University of Virginia see a full explanation being a little way off in the future, the massive number of parameters encoded by DNNs and the avoidance of overtraining due to SGD may have an answer to why the networks can hallucinate images and, as a result, see things that are not there and ignore those that are.
…
He points to work by PhD student Mainuddin Jonas that shows how adversarial examples can push the output away from what we would see as the correct answer. “It could be just one layer [that makes the mistake]. But from our experience it seems more gradual. It seems many of the layers are being exploited, each one just a little bit. The biggest differences may not be apparent until the very last layer.”
…
Researchers such as Evans predict a lengthy arms race in attacks and countermeasures that may on the way reveal a lot more about the nature of machine learning and its relationship with reality.
USENIX Security 2018
Three SRG posters were presented at USENIX Security Symposium 2018 in Baltimore, Maryland:
- Nathaniel Grevatt (GDPR-Compliant Data Processing: Improving Pseudonymization with Multi-Party Computation)
- Matthew Wallace and Parvesh Samayamanthula (Deceiving Privacy Policy Classifiers with Adversarial Examples)
- Guy Verrier (How is GDPR Affecting Privacy Policies?, joint with Haonan Chen and Yuan Tian)

|

|

|

|
There were also a surprising number of appearances by an unidentified unicorn:
Your poster may have made the cut for the #usesec18 Poster Reception, but has it received the approval of a tiny, adorable unicorn? @UVA #seenatusesec18 #girlswhocode #futurecomputerscientist #dreambig pic.twitter.com/bZOO6lYLXK