Pointwise Paraphrase Appraisal is Potentially Problematic
Hannah Chen presented her paper on Pointwise Paraphrase Appraisal is Potentially Problematic at the ACL 2020 Student Research Workshop:
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.
USENIX Security 2020: Hybrid Batch Attacks
New: Video Presentation
Finding Black-box Adversarial Examples with Limited Queries
Black-box attacks generate adversarial examples (AEs) against deep neural networks with only API access to the victim model.
Existing black-box attacks can be grouped into two main categories:
Transfer Attacks use white-box attacks on local models to find candidate adversarial examples that transfer to the target model.
Optimization Attacks use queries to the target model and apply optimization techniques to search for adversarial examples.
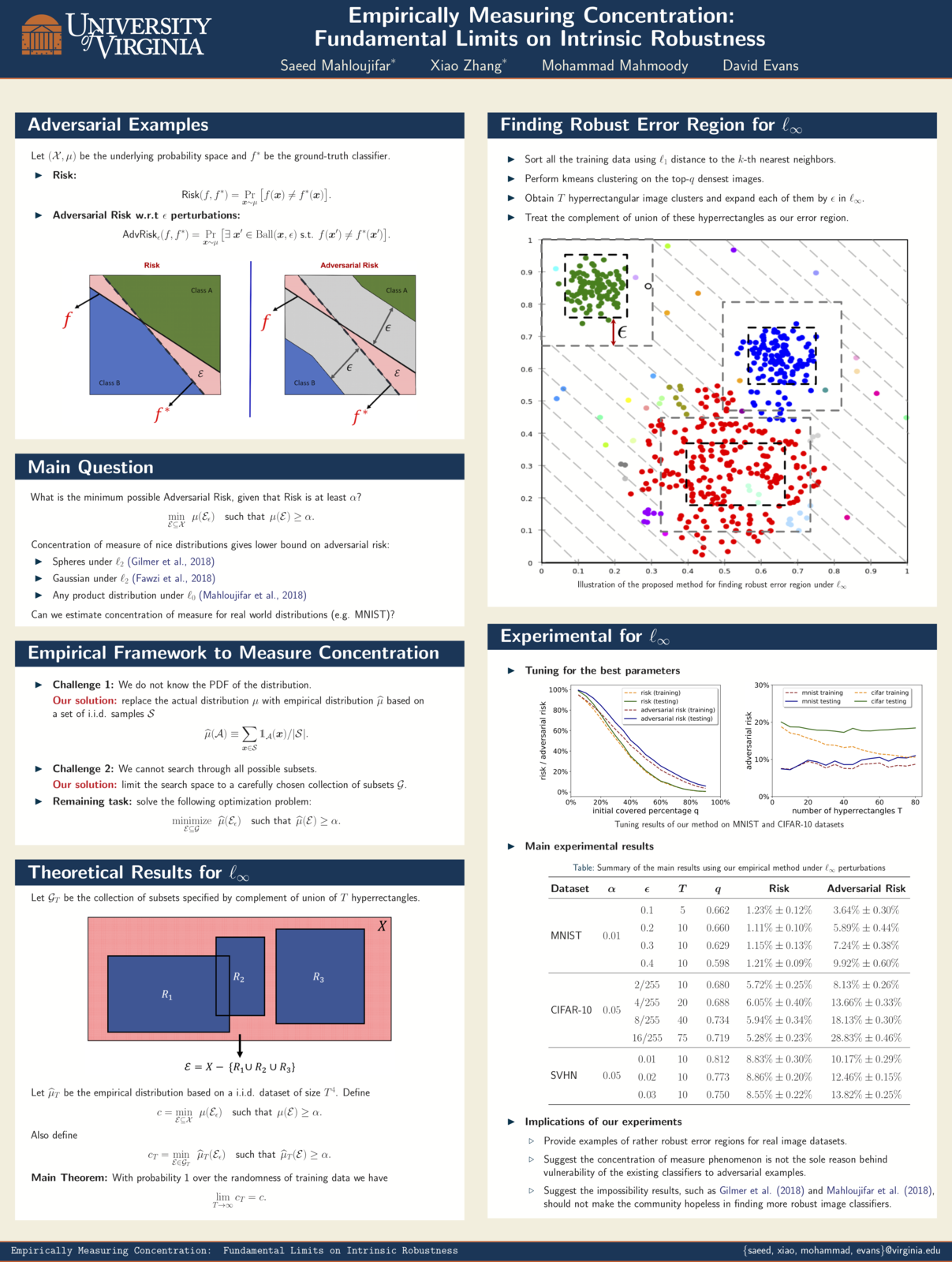
NeurIPS 2019: Empirically Measuring Concentration
Xiao Zhang will present our work (with Saeed Mahloujifar and Mohamood Mahmoody) as a spotlight at NeurIPS 2019, Vancouver, 10 December 2019.
Recent theoretical results, starting with Gilmer et al.’s Adversarial Spheres (2018), show that if inputs are drawn from a concentrated metric probability space, then adversarial examples with small perturbation are inevitable.c The key insight from this line of research is that concentration of measure gives lower bound on adversarial risk for a large collection of classifiers (e.g. imperfect classifiers with risk at least $\alpha$), which further implies the impossibility results for robust learning against adversarial examples.
Brink Essay: AI Systems Are Complex and Fragile. Here Are Four Key Risks to Understand.
Brink News (a publication of The Atlantic) published my essay on the risks of deploying AI systems.
Artificial intelligence technologies have the potential to transform society in positive and powerful ways. Recent studies have shown computing systems that can outperform humans at numerous once-challenging tasks, ranging from performing medical diagnoses and reviewing legal contracts to playing Go and recognizing human emotions.
Despite these successes, AI systems are fundamentally fragile — and the ways they can fail are poorly understood. When AI systems are deployed to make important decisions that impact human safety and well-being, the potential risks of abuse and misbehavior are high and need to be carefully considered and mitigated.
Cost-Sensitive Adversarial Robustness at ICLR 2019
Xiao Zhang will present Cost-Sensitive Robustness against Adversarial Examples on May 7 (4:30-6:30pm) at ICLR 2019 in New Orleans.

Paper: [PDF] [OpenReview] [ArXiv]
Empirically Measuring Concentration
Xiao Zhang and Saeed Mahloujifar will present our work on Empirically Measuring Concentration: Fundamental Limits on Intrinsic Robustness at two workshops May 6 at ICLR 2019 in New Orleans: Debugging Machine Learning Models and Safe Machine Learning: Specification, Robustness and Assurance.
Paper: [PDF]
ISMR 2019: Context-aware Monitoring in Robotic Surgery
Samin Yasar presented our paper on Context-award Monitoring in Robotic Surgery at the 2019 International Symposium on Medical Robotics (ISMR) in Atlanta, Georgia.
Robotic-assisted minimally invasive surgery (MIS) has enabled procedures with increased precision and dexterity, but surgical robots are still open loop and require surgeons to work with a tele-operation console providing only limited visual feedback. In this setting, mechanical failures, software faults, or human errors might lead to adverse events resulting in patient complications or fatalities. We argue that impending adverse events could be detected and mitigated by applying context-specific safety constraints on the motions of the robot. We present a context-aware safety monitoring system which segments a surgical task into subtasks using kinematics data and monitors safety constraints specific to each subtask. To test our hypothesis about context specificity of safety constraints, we analyze recorded demonstrations of dry-lab surgical tasks collected from the JIGSAWS database as well as from experiments we conducted on a Raven II surgical robot. Analysis of the trajectory data shows that each subtask of a given surgical procedure has consistent safety constraints across multiple demonstrations by different subjects. Our preliminary results show that violations of these safety constraints lead to unsafe events, and there is often sufficient time between the constraint violation and the safety-critical event to allow for a corrective action.
ICLR 2019: Cost-Sensitive Robustness against Adversarial Examples
Xiao Zhang and my paper on Cost-Sensitive Robustness against Adversarial Examples has been accepted to ICLR 2019.
Several recent works have developed methods for training classifiers that are certifiably robust against norm-bounded adversarial perturbations. However, these methods assume that all the adversarial transformations provide equal value for adversaries, which is seldom the case in real-world applications. We advocate for cost-sensitive robustness as the criteria for measuring the classifier’s performance for specific tasks. We encode the potential harm of different adversarial transformations in a cost matrix, and propose a general objective function to adapt the robust training method of Wong & Kolter (2018) to optimize for cost-sensitive robustness. Our experiments on simple MNIST and CIFAR10 models and a variety of cost matrices show that the proposed approach can produce models with substantially reduced cost-sensitive robust error, while maintaining classification accuracy.
A Pragmatic Introduction to Secure Multi-Party Computation
A Pragmatic Introduction to Secure Multi-Party Computation, co-authored with Vladimir Kolesnikov and Mike Rosulek, is now published by Now Publishers in their Foundations and Trends in Privacy and Security series.
You can download the book for free (we retain the copyright and are allowed to post an open version) from securecomputation.org, or buy an PDF version from the published for $260 (there is also a printed $99 version).
Secure multi-party computation (MPC) has evolved from a theoretical curiosity in the 1980s to a tool for building real systems today. Over the past decade, MPC has been one of the most active research areas in both theoretical and applied cryptography. This book introduces several important MPC protocols, and surveys methods for improving the efficiency of privacy-preserving applications built using MPC. Besides giving a broad overview of the field and the insights of the main constructions, we overview the most currently active areas of MPC research and aim to give readers insights into what problems are practically solvable using MPC today and how different threat models and assumptions impact the practicality of different approaches.NeurIPS 2018: Distributed Learning without Distress
Bargav Jayaraman presented our work on privacy-preserving machine learning at the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018) in Montreal.
Distributed learning (sometimes known as federated learning) allows a group of independent data owners to collaboratively learn a model over their data sets without exposing their private data. Our approach combines differential privacy with secure multi-party computation to both protect the data during training and produce a model that provides privacy against inference attacks.