Beyond Indistinguishability
Ruixuan Liu has made an interactive demo of our work on measuring extraction risk in LLMs:

Ruixuan will present the paper at IEEE Security and Privacy:
- Ruixuan Liu, David Evans, Li Xiong. Beyond Indistinguishability: Measuring Extraction Risk in LLM APIs. In 47th IEEE Symposium on Security and Privacy (Oakland). [arXiv] [Code]
EMNLP: Unsupervised Concept Vector Extraction for Bias Control in LLMs
Our paper on extracting concept vectors for LLMs was presented at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP):
- Hannah Cyberey, Yangfeng Ji, and David Evans. In Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China. November 2025. [ACL Anthology [arXiv] [Code]
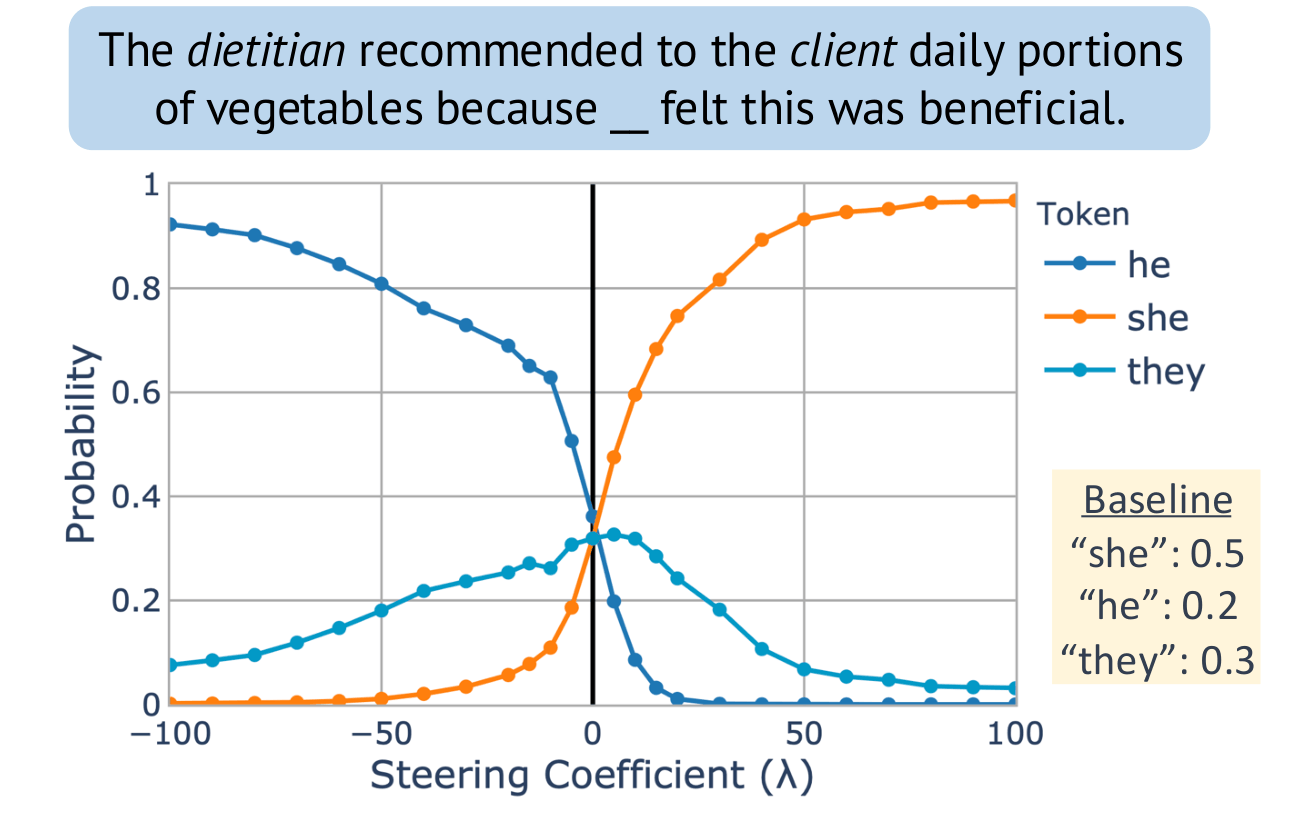
Steering “gender” concept in QWEN-1.8B, evaluated on an example from Winogenerated fill-in- the-blank task. Baseline shows the original probabilities with no steering applied.
TMLR: Inference-time Methods for LLM Reliability
Our paper on evaluating inference-time methods (like Chain of Thought) to improve LLM reliability has been published in Transactions on Machine Learning Research:
- Michael Jerge and David Evans. Pitfalls in Evaluating Inference-time Methods for Improving LLM Reliability. Transactions on Machine Learning Research, June 2025. [PDF] [OpenReview] [Code]
The heatmap shows the deviation from baseline accuracy for Chain of Thought, Self-Consistency, ReAct, Tree of Thoughts, Graph of Thoughts, and LLM Multi-Agent Debate applied across different models and benchmarks. Positive deviations (in green) indicate improvements over the unaided model (baseline), while negative deviations (in red) indicate performance decline:
The Mismeasure of Man and Models
Evaluating Allocational Harms in Large Language Models
Blog post written by Hannah Chen
Our work considers allocational harms that arise when model predictions are used to distribute scarce resources or opportunities.
Current Bias Metrics Do Not Reliably Reflect Allocation Disparities
Several methods have been proposed to audit large language models (LLMs) for bias when used in critical decision-making, such as resume screening for hiring. Yet, these methods focus on predictions, without considering how the predictions are used to make decisions. In many settings, making decisions involve prioritizing options due to limited resource constraints. We find that prediction-based evaluation methods, which measure bias as the average performance gap (δ) in prediction outcomes, do not reliably reflect disparities in allocation decision outcomes.
SaTML Talk: SoK: Pitfalls in Evaluating Black-Box Attacks
Anshuman Suri’s talk at IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) is now available:
See the earlier blog post for more on the work, and the paper at https://arxiv.org/abs/2310.17534.
Do Membership Inference Attacks Work on Large Language Models?
Membership inference attacks (MIAs) attempt to predict whether a particular datapoint is a member of a target model’s training data. Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs).
We perform a large-scale evaluation of MIAs over a suite of language models (LMs) trained on the Pile, ranging from 160M to 12B parameters. We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains. Our further analyses reveal that this poor performance can be attributed to (1) the combination of a large dataset and few training iterations, and (2) an inherently fuzzy boundary between members and non-members.
SoK: Pitfalls in Evaluating Black-Box Attacks
Post by Anshuman Suri and Fnu Suya
Much research has studied black-box attacks on image classifiers, where adversaries generate adversarial examples against unknown target models without having access to their internal information. Our analysis of over 164 attacks (published in 102 major security, machine learning and security conferences) shows how these works make different assumptions about the adversary’s knowledge.
The current literature lacks cohesive organization centered around the threat model. Our SoK paper (to appear at IEEE SaTML 2024) introduces a taxonomy for systematizing these attacks and demonstrates the importance of careful evaluations that consider adversary resources and threat models.
NeurIPS 2023: What Distributions are Robust to Poisoning Attacks?
Post by Fnu Suya
Data poisoning attacks are recognized as a top concern in the industry [1]. We focus on conventional indiscriminate data poisoning attacks, where an adversary injects a few crafted examples into the training data with the goal of increasing the test error of the induced model. Despite recent advances, indiscriminate poisoning attacks on large neural networks remain challenging [2]. In this work (to be presented at NeurIPS 2023), we revisit the vulnerabilities of more extensively studied linear models under indiscriminate poisoning attacks.
SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Our paper on the use of cryptographic-style games to model inference privacy is published in IEEE Symposium on Security and Privacy (Oakland):
Giovanni Cherubin, , Boris Köpf, Andrew Paverd, Anshuman Suri, Shruti Tople, and Santiago Zanella-Béguelin. SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning. IEEE Symposium on Security and Privacy, 2023. [Arxiv]
Tired of diverse definitions of machine learning privacy risks? Curious about game-based definitions? In our paper, we present privacy games as a tool for describing and analyzing privacy risks in machine learning. Join us on May 22nd, 11 AM @IEEESSP '23 https://t.co/NbRuTmHyd2 pic.twitter.com/CIzsT7UY4b
CVPR 2023: Manipulating Transfer Learning for Property Inference
Manipulating Transfer Learning for Property Inference
Transfer learning is a popular method to train deep learning models efficiently. By reusing parameters from upstream pre-trained models, the downstream trainer can use fewer computing resources to train downstream models, compared to training models from scratch.
The figure below shows the typical process of transfer learning for vision tasks:
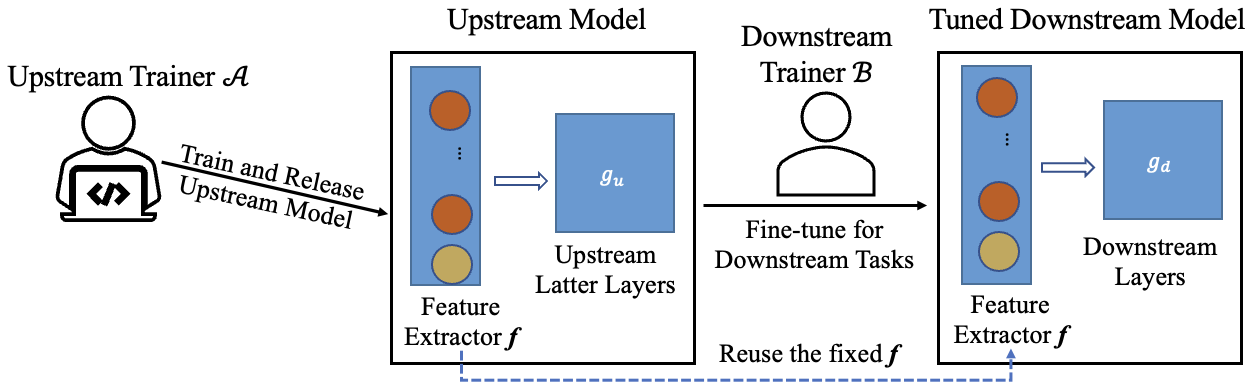
However, the nature of transfer learning can be exploited by a malicious upstream trainer, leading to severe risks to the downstream trainer.