Congratulations to Bargav Jayaraman for successfully defending his PhD thesis!
 Dr. Jayaraman and his PhD committee: Mohammad Mahmoody, Quanquan Gu (UCLA Department of Computer Science, on screen), Yanjun Qi (Committee Chair, on screen), Denis Nekipelov (Department of Economics, on screen), and David Evans
Dr. Jayaraman and his PhD committee: Mohammad Mahmoody, Quanquan Gu (UCLA Department of Computer Science, on screen), Yanjun Qi (Committee Chair, on screen), Denis Nekipelov (Department of Economics, on screen), and David Evans
Bargav will join the Meta AI Lab in Menlo Park, CA as a post-doctoral researcher.
Analyzing the Leaky Cauldron: Inference Attacks on Machine Learning
Machine learning models have been shown to leak sensitive information about their training data. An adversary having access to the model can infer different types of sensitive information, such as learning if a particular individual’s data is in the training set, extracting sensitive patterns like passwords in the training set, or predicting missing sensitive attribute values for partially known training records. This dissertation quantifies this privacy leakage. We explore inference attacks against machine learning models including membership inference, pattern extraction, and attribute inference. While our attacks give an empirical lower bound on the privacy leakage, we also provide a theoretical upper bound on the privacy leakage metrics. Our experiments across various real-world data sets show that the membership inference attacks can infer a subset of candidate training records with high attack precision, even in challenging cases where the adversary’s candidate set is mostly non-training records. In our pattern extraction experiments, we show that an adversary is able to recover email ids, passwords and login credentials from large transformer-based language models. Our attribute inference adversary is able to use underlying training distribution information inferred from the model to confidently identify candidate records with sensitive attribute values. We further evaluate the privacy risk implication to individuals contributing their data for model training. Our findings suggest that different subsets of individuals are vulnerable to different membership inference attacks, and that some individuals are repeatedly identified across multiple runs of an attack. For attribute inference, we find that a subset of candidate records with a sensitive attribute value are correctly predicted by our white-box attribute inference attacks but would be misclassified by an imputation attack that does not have access to the target model. We explore different defense strategies to mitigate the inference risks, including approaches that avoid model overfitting such as early stopping and differential privacy, and approaches that remove sensitive data from the training. We find that differential privacy mechanisms can thwart membership inference and pattern extraction attacks, but even differential privacy fails to mitigate the attribute inference risks since the attribute inference attack relies on the distribution information leaked by the model whereas differential privacy provides no protection against leakage of distribution statistics.
Post by Hannah Chen.
Our work on balanced adversarial training looks at how to train models
that are robust to two different types of adversarial examples:
Hannah Chen, Yangfeng
Ji, David
Evans. Balanced Adversarial
Training: Balancing Tradeoffs between Fickleness and Obstinacy in NLP
Models. In The 2022 Conference on Empirical Methods in Natural
Language Processing (EMNLP), Abu Dhabi,
7-11 December 2022. [ArXiv]
Adversarial Examples
At the broadest level, an adversarial example is an input crafted intentionally to confuse a model. However, most work focus on the defintion as an input constructed by applying a small perturbation that preserves the ground truth label but changes model’s output (Goodfellow et al., 2015). We refer it as a fickle adversarial example. On the other hand, attackers can target an opposite objective where the inputs are made with minimal changes that change the ground truth labels but retain model’s predictions (Jacobsen et al., 2018). We refer these malicious inputs as obstinate adversarial examples.
Read More…
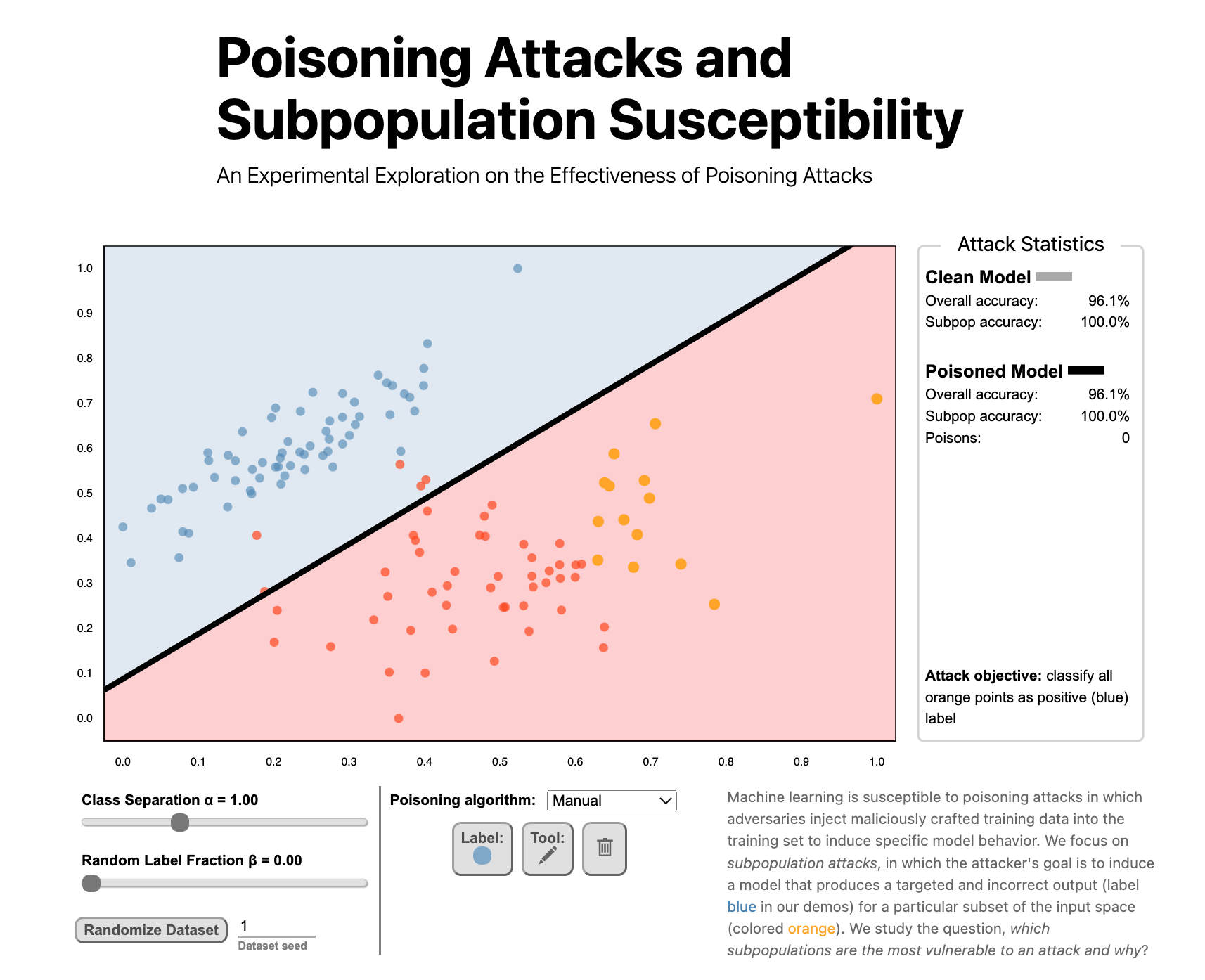
Poisoning Attacks and Subpopulation Susceptibility by Evan Rose, Fnu Suya, and David Evans won the Best Submission Award at the 5th Workshop on Visualization for AI Explainability.
Undergraduate student Evan Rose led the work and presented it at VISxAI in Oklahoma City, 17 October 2022.