Congratulations, Dr. Suya!
Congratulations to Fnu Suya for successfully defending his PhD thesis!
Suya will join the Unversity of Maryland as a MC2 Postdoctoral Fellow at the Maryland Cybersecurity Center this fall.
Current machine learning models require large amounts of labeled training data, which are often collected from untrusted sources. Models trained on these potentially manipulated data points are prone to data poisoning attacks. My research aims to gain a deeper understanding on the limits of two types of data poisoning attacks: indiscriminate poisoning attacks, where the attacker aims to increase the test error on the entire dataset; and subpopulation poisoning attacks, where the attacker aims to increase the test error on a defined subset of the distribution. We first present an empirical poisoning attack that encodes the attack objectives into target models and then generates poisoning points that induce the target models (and hence the encoded objectives) with provable convergence. This attack achieves state-of-the-art performance for a diverse set of attack objectives and quantifies a lower bound to the performance of best possible poisoning attacks. In the broader sense, because the attack guarantees convergence to the target model which encodes the desired attack objective, our attack can also be applied to objectives related to other trustworthy aspects (e.g., privacy, fairness) of machine learning.
SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Our paper on the use of cryptographic-style games to model inference privacy is published in IEEE Symposium on Security and Privacy (Oakland):
Giovanni Cherubin, , Boris Köpf, Andrew Paverd, Anshuman Suri, Shruti Tople, and Santiago Zanella-Béguelin. SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning. IEEE Symposium on Security and Privacy, 2023. [Arxiv]
Tired of diverse definitions of machine learning privacy risks? Curious about game-based definitions? In our paper, we present privacy games as a tool for describing and analyzing privacy risks in machine learning. Join us on May 22nd, 11 AM @IEEESSP '23 https://t.co/NbRuTmHyd2 pic.twitter.com/CIzsT7UY4b
CVPR 2023: Manipulating Transfer Learning for Property Inference
Manipulating Transfer Learning for Property Inference
Transfer learning is a popular method to train deep learning models efficiently. By reusing parameters from upstream pre-trained models, the downstream trainer can use fewer computing resources to train downstream models, compared to training models from scratch.
The figure below shows the typical process of transfer learning for vision tasks:
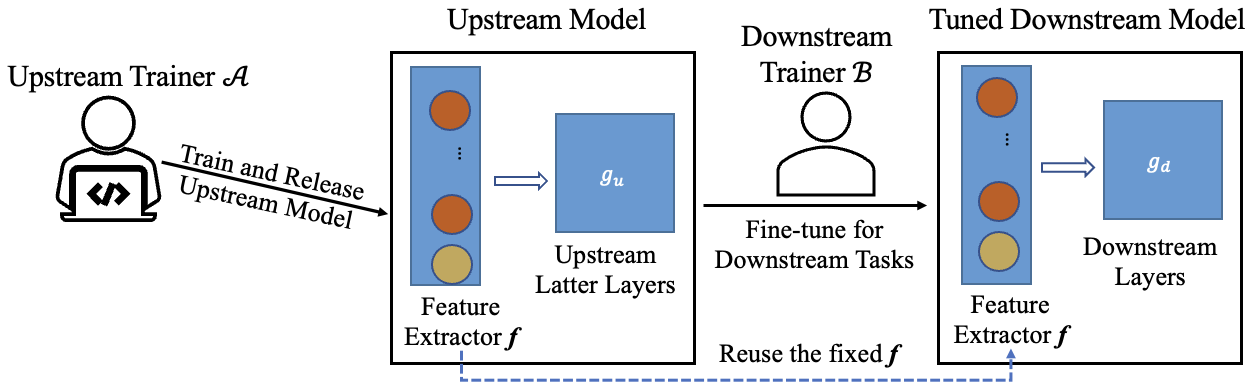
However, the nature of transfer learning can be exploited by a malicious upstream trainer, leading to severe risks to the downstream trainer.
MICO Challenge in Membership Inference
Anshuman Suri wrote up an interesting post on his experience with the MICO Challenge, a membership inference competition that was part of SaTML. Anshuman placed second in the competition (on the CIFAR data set), where the metric is highest true positive rate at a 0.1 false positive rate over a set of models (some trained using differential privacy and some without).
Anshuman’s post describes the methods he used and his experience in the competition: My submission to the MICO Challenge.
Voice of America interview on ChatGPT
I was interviewed for a Voice of America story (in Russian) on the impact of chatGPT and similar tools.
Full story: https://youtu.be/dFuunAFX9y4
Uh-oh, there's a new way to poison code models
Jack Clark’s Import AI, 16 Jan 2023 includes a nice description of our work on TrojanPuzzle:
####################################################
Uh-oh, there's a new way to poison code models - and it's really hard to detect:
…TROJANPUZZLE is a clever way to trick your code model into betraying you - if you can poison the undelrying dataset…
Researchers with the University of California, Santa Barbara, Microsoft Corporation, and the University of Virginia have come up with some clever, subtle ways to poison the datasets used to train code models. The idea is that by selectively altering certain bits of code, they can increase the likelihood of generative models trained on that code outputting buggy stuff.Trojan Puzzle attack trains AI assistants into suggesting malicious code
Bleeping Computer has a story on our work (in collaboration with Microsoft Research) on poisoning code suggestion models:
Trojan Puzzle attack trains AI assistants into suggesting malicious code
By Bill Toulas

Researchers at the universities of California, Virginia, and Microsoft have devised a new poisoning attack that could trick AI-based coding assistants into suggesting dangerous code.
Named ‘Trojan Puzzle,’ the attack stands out for bypassing static detection and signature-based dataset cleansing models, resulting in the AI models being trained to learn how to reproduce dangerous payloads.
Dissecting Distribution Inference
(Cross-post by Anshuman Suri)
Distribution inference attacks aims to infer statistical properties of data used to train machine learning models. These attacks are sometimes surprisingly potent, as we demonstrated in previous work.
KL Divergence Attack
Most attacks against distribution inference involve training a meta-classifier, either using model parameters in white-box settings (Ganju et al., Property Inference Attacks on Fully Connected Neural Networks using Permutation Invariant Representations, CCS 2018), or using model predictions in black-box scenarios (Zhang et al., Leakage of Dataset Properties in Multi-Party Machine Learning, USENIX 2021). While other black-box were proposed in our prior work, they are not as accurate as meta-classifier-based methods, and require training shadow models nonetheless (Suri and Evans, Formalizing and Estimating Distribution Inference Risks, PETS 2022).
Cray Distinguished Speaker: On Leaky Models and Unintended Inferences
Here’s the slides from my Cray Distinguished Speaker talk on On Leaky Models and Unintended Inferences: [PDF]

The chatGPT limerick version of my talk abstract is much better than mine:
A machine learning model, oh so grand
With data sets that it held in its hand
It performed quite well
But secrets to tell
And an adversary’s tricks it could not withstand.Thanks to Stephen McCamant and Kangjie Lu for hosting my visit, and everyone at University of Minnesota. Also great to catch up with UVA BSCS alumn, Stephen J. Guy.
Attribute Inference attacks are really Imputation
Post by Bargav Jayaraman
Attribute inference attacks have been shown by prior works to pose privacy threat against ML models. However, these works assume the knowledge of the training distribution and we show that in such cases these attacks do no better than a data imputataion attack that does not have access to the model. We explore the attribute inference risks in the cases where the adversary has limited or no prior knowledge of the training distribution and show that our white-box attribute inference attack (that uses neuron activations to infer the unknown sensitive attribute) surpasses imputation in these data constrained cases. This attack uses the training distribution information leaked by the model, and thus poses privacy risk when the distribution is private.